
Clustering Reorg. 를 이용한 튜닝사례
Updated:
Clustering Reorg. 를 수행함
얼마 전 어떤 테이블에 대한 Clustering Reorg 를 수행한 적이 있었다. 여기서 Table Clustering Reorg 이라는 말은 필자가 붙인 용어인데, ‘Cluster’ 에 중점이 있다. Oracle DBMS 에서 Cluster 라는 단어를 쓰는 용어들 중에 Clustered Table 과 Clustering Factor 가 있다. 이 용어들에서 ‘Cluster’ 의 의미는 ‘모여있다’ 의 의미로 쓰인다. 구체적으로는 데이터가 모여서 저장되어 있다는 의미이다.
Clustered Table 은 Cluster segment 에 데이터를 저장한 테이블을 말한다.(일반적인 테이블은 Normal Heap segment 에 데이터를 저장한다.) Clustered Table 의 특징은 Cluster Key 값이 같은 데이터들을 같은 블럭에 저장한다는 것이다. 즉 Cluster key 값이 같은 Row 들이 물리적으로 모여 있다는 것인데, 이런 상태를 가리켜 Cluster Key 값에 대하여 Clustering Factor 가 좋다라고 한다.
Clustering Factor 가 좋으면(다시 말해, 모여있는 정도가 좋으면 또는 잘 모여 있으면) 특정 키값(Cluster Key 값 또는 Index Key 값)을 조건으로 데이터를 액세스할 때, 최소의 블럭을 액세스하여 결과를 얻을 수 있다.
일반 테이블에서 Clustering Factor 가 좋다는 의미는 그 테이블에 생성되어 있는 한 인덱스에 대해서 높다는 의미이다. 즉, 다른 인덱스에 대해서는 Clustering Factor 가 나쁠 수 있다.
예를 들어 판매 테이블에서 판매일 열에 인덱스 A 가 있고 고객번호 열에 인덱스 B 가 있다면, 판매 테이블은 A 인덱스에 대해서는 Clustering Factor 가 좋을 것이고 B 인덱스에 대해서는 Clustering Factor 가 별로 좋지 않을 것이다. 왜냐 하면 판매 테이블 특성상 판매일이 같은 Row 들이 모여 저장될 가능성이 높기 때문이다. 반면에 고객번호 열 값이 같은 Row 들이 모여 저장될 가능성은 별로 없을 것이다.
그런데, 만약 판매 테이블을 검색하는 쿼리의 조건이 고객번호라고 한다면 어떨까? 특정 고객의 판매 Row 들은 여러 블럭들에 흩어져 저장되어져 있을 것이다. 이 때문에 쿼리에서 액세스해야 하는 블럭들이 많을 것이며 disk read 도 따라서 많이 발생될 것이고, 결과적으로 응답시간은 늦어질 것이다.
만일 판매 테이블에 적재되어 있는 Row 들을 고객번호 열을 기준으로 정렬해서 다시 적재한다면 어떨까? 그렇게 한다면 특정 고객의 Row 들은 최대한 적은 블럭들 안에 모여서 저장될 것이고, 쿼리는 최소의 블럭들만을 액세스 할 것이며, 당연히 disk read 도 적게 발생될 것이고 응답시간도 자연히 빨라질 것이다.
이렇게 일반 테이블에서 특정 검색조건(인덱스가 만들어져 있는) 열을 기준으로 Row 들을 재적재하는 것을 Clustering Reorg. 라고 필자는 부르는 것이다.
Clustered Table 에서는 Clustering 적재를 강제하므로 Row 들의 Clustering 이 항상 유지되지만 일반 테이블에서는 Clustering Reorg. 이후에 적재되는 Row 들은 자유롭게 어떤 블럭에도 저장될 수 있으므로 시간이 지남에 따라 Clustering Factor 는 점점 나빠지게 될 것이다. 그러므로 일반 테이블은 가끔씩 Clustering Reorg. 작업을 수행해 줄 필요가 생긴다.
Clustering Factor 관점에서 볼 때, Clustering Factor 가 가장 좋은 테이블은 그 이름에서 알 수 있듯 당연히 Clustered Table 이다. 그 다음은 Partitioned Table 이라고 할 수 있다. Partition Key 값이 같은 Row 들이 같은 Partition segment 에 저장되기 때문이다. 물론 같은 partition segment 안에서의 Clustering 은 강제할 수 없다. Partitioning Level 을 년에서 월로 더 세분시킨다면 Clustering Factor 는 더 좋아질 것이다.
아래는 얼마 전 수행했던 판매 테이블의 고객번호에 대한 Clustering Reorg. 수행 결과이다.
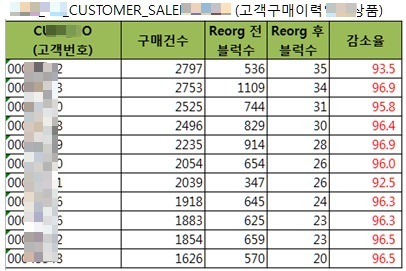
Clustering Reorg. 후 고객번호에 대하여 Clustering Factor 가 좋아졌음
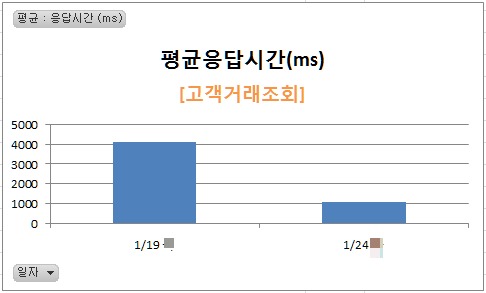
고객거래조회 평균응답시간이 개선되었음
Logical read 도 20% 정도 줄었지만 무엇보다 Disk read 가 줄어든 덕에 평균응답시간이 빨라졌다.
10여년 전에 김포 00병원 튜닝 때에도 비슷한 경험이 있었다.
환자진료기록 테이블은 의사가 환자를 진료할 때 읽어야 할 데이터들이 저장되어 있는 테이블이다. 이 테이블의 특징은 환자가 진료를 위해 병원을 방문할 때마다 데이터가 저장되는 시계열성 테이블이라는 것이다. 즉, 진료일 칼럼에 대하여는 Clustering Factor 가 좋지만 환자번호 칼럼에 대해서는 Clustering Factor 가 좋지 않은 것이다.
환자가 진료를 위해 방문했을 때 이 환자의 진료기록들을 보기 위해 의사는 환자번호를 검색조건으로 진료기록 테이블을 검색한다. 이 경우 Clustering Factor 가 좋지 않으므로 많은 블럭들을 액세스해야 하기 때문에 화면 속도가 좋지 않았다. (여기에 페이징 및 부분범위처리까지 되어있지 않았었으니 진료기록이 수백건인 단골환자의 화면이 뜨는데는 1분이나 걸리기도 했었다.)
이를 해결하기 위해 당시 필자는 환자번호를 Key 로 한 Index Clustered Table 로 테이블의 저장구조를 전환시켰었다. 결과는 좋아서 의사들의 큰 불편이 해소되었다.
앞서의 예처럼 고객별 판매테이블이나 환자진료기록 테이블처럼 주로 특정의 칼럼을 검색조건으로 액세스가 일어나는 시계열성 테이블이라면 Clustering Factor 에 대한 진지한 고민이 필요할 수 있다. 상황에 따라 일반 테이블 세그먼트에서의 Clustering Reorg. 를 선택할 수도, 아니면 아예 Cluster segment 로의 저장방식 전환을 선택할 수도 있을 것이다. 그것은 의사가 환자의 치료방법을 고민하고 선택하듯 오롯이 그 상황 속에 들어가 있는 엔지니어의 몫이다.
[Note]
앞서의 판매테이블에 대한 Clustering Reorg. 작업 때 일이다. 이때, 고객마스터 테이블도 관리매장열을 기준으로 함께 Clustering Reorg. 를 수행했었는데 이 테이블엔 자동금액계산용 트리거가 몇개 달려 있었다. Reorg 스크립트를 작성할 때 원래 테이블을 Rename 시킨 후 빈 고객마스터 테이블을 만들고, 데이터를 옮기는 방식으로 작업스크립트를 작성했다. 이때, 트리거는 Disable 후 Enable 하면 안된다. 반드시 Drop 하고 다시 Create 해야 한다. 트리거는 Dependent Object 이기 때문에 Mother Object (테이블) 가 Rename 되어도 참조링크가 깨지지 않는다. 테이블을 Rename 해도 인덱스의 참조링크가 깨지지 않는 것과 마찬가지이다. 만일 위 트리거들을 Drop 하고 다시 Create 하지 않고 Disable 후 Enable 했다면 트리거들은 새로 만든 마스터 테이블에 걸리지 않고 원래의 마스터 테이블을 참조하게 되어 자동금액계산이 되지않아 장애로 이어졌을 것이다. 자칫하면 위험천만한 상황이 생길 뻔 했었던 것이다.
일반적으로 트리거는 잘 쓰지 않기도 해서 트리거가 달린 테이블을 Reorg. 하는 일이 흔하지는 않지만, 만일 트리거가 달린 테이블을 Reorg. 하기로 했다면 반드시 트리거의 참조관계를 확인해야 한다.