모니터링과 추적 패턴
Updated:
- 다양한 서비스 등록, 탐색 위한 Service registry , Service discovery 패턴
- 서비스 단일 진입을 위한 API 게이트웨이(gateway) 패턴 & BFF(Backend For Frontend) 패턴
- 외부 구성 저장소 패턴
- 마이크로서비스 인증/인가 패턴
- 장애 및 실패 처리를 위한 서킷 브레이크 패턴
- 모니터링과 추적 패턴
- 중앙화된 로그 집계 패턴
- 서비스 매시(Service Mesh) 패턴
모니터링과 추적 패턴
그렇다면 이런 마이크로서비스의 장애를 어떻게 감지할 수 있을까? 이런 서킷 브레이커 패턴을 가능하도록 하기위해서는 각 마이크로서비스의 장애를 실시간으로 감지해야 하고 어떤 서비스간의 호출이 있는지 알아야 한다. 즉 모니터링하고 추적하는 패턴이 필요하다. 스프링 클라우드에서 히스트릭스(Hystrix)라는 라이브러리를 제공하고 이를 모니터링 할 수 있는 대시보드로 히스트릭 대시보드를(Hystrix Dashboard) 제공한다. 아래 그림과 같이 지정된 마이크로서비스들의 메서드를 실시간으로 모니터링 할 수 있다.
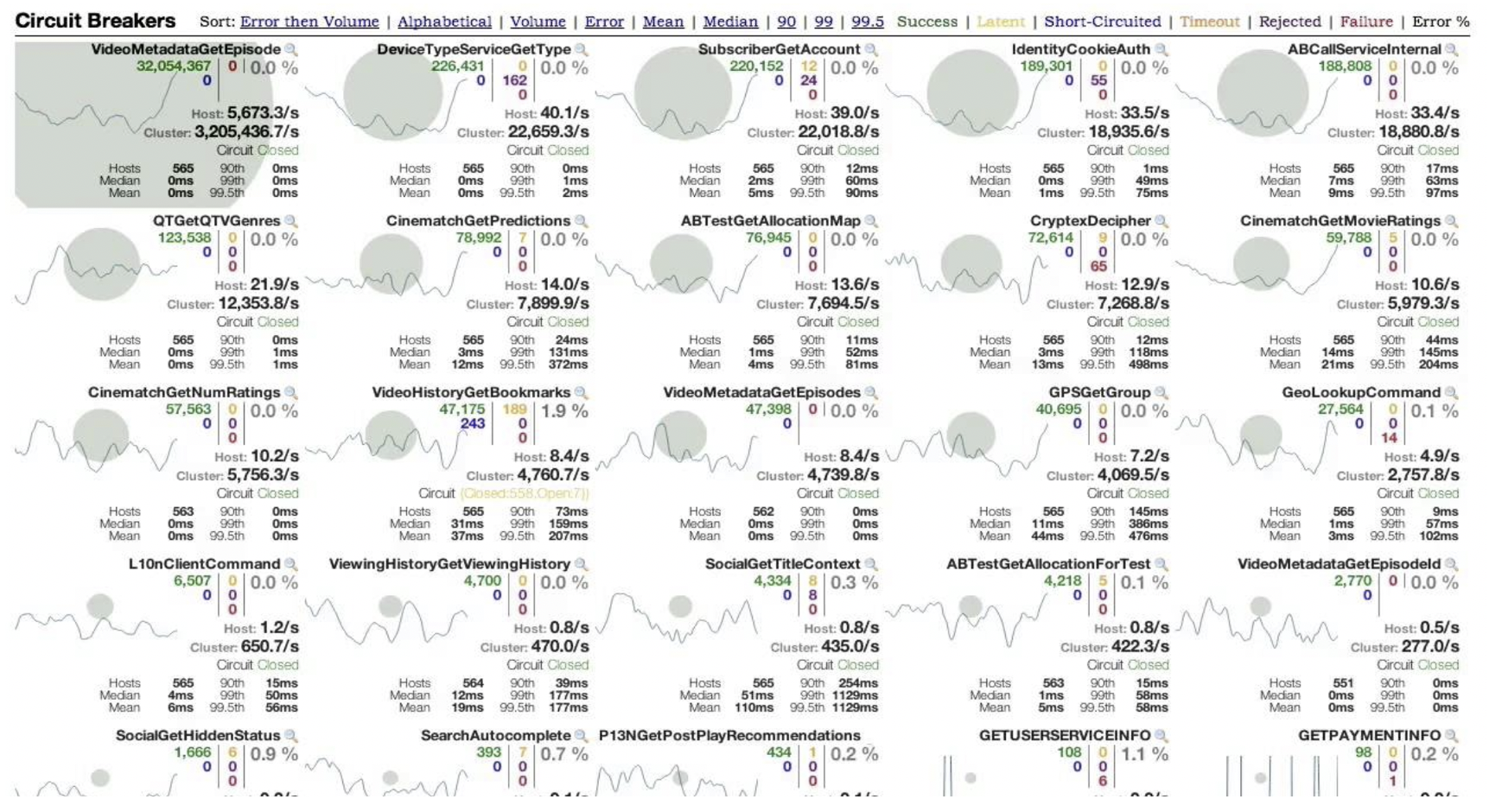
그림을 보면 각 메서드에 각각의 트래픽 양이 원으로 표현되는 것을 볼 수 있다. 원이 클수록 트래픽 양이 많은 것이다. 그러다가 서비스 성능에 문제가 발생하면 서킷이 오픈 되고 적색으로 표현된다. 그럼 서킷브레이크가 발동된 것이다. 이렇게 마이크로서비스를 모니터링 하다가 적절한 조치를 취할 수 있게 된다.
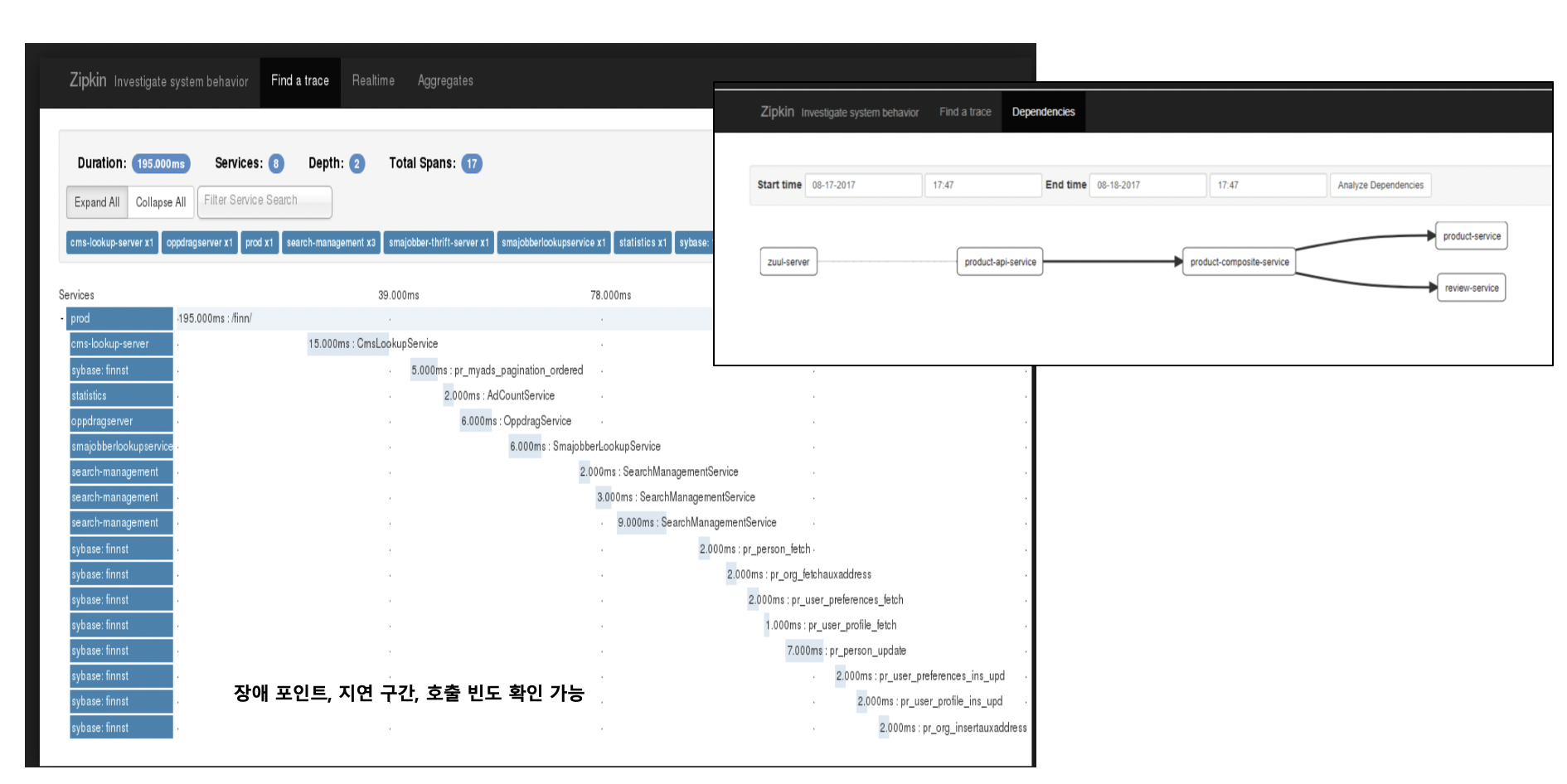
다음은 분산 트레이싱 서비스다. 모니터링과 함께 각각의 서비스 트랜잭션의 호출을 추적하면 운영에 매우 유용하다. 예시로 트위터에서 공개한 집킨(Zipkin)이라는 오픈 소스를 보면 다음과 그림과 같이 분산된 서비스 간의 호출이나 지연 구간별 장애 포인트를 확인할 수 있다. 또한 서비스 API를 선택해 보면 이렇게 각 API가 다른 API를 어떻게 호출하는지 호출 시의 반응 시간이나 지연 구간 등을 확인할 수 있다. 그리고 정적인 다이어그램도 제공하여 전체적인 API간의 호출 빈도도 확인할 수 있다. 이 다이어그램을 운영자가 실시간으로 보다가 만약 호출 빈도가 너무 많은 API나 반응 시간이 높은 API가 있다면 이를 개선할 수 있을 것이다.