
다양한 서비스 등록, 탐색 위한 Service registry , Service discovery 패턴
Updated:
- 다양한 서비스 등록, 탐색 위한 Service registry , Service discovery 패턴
- 서비스 단일 진입을 위한 API 게이트웨이(gateway) 패턴 & BFF(Backend For Frontend) 패턴
- 외부 구성 저장소 패턴
- 마이크로서비스 인증/인가 패턴
- 장애 및 실패 처리를 위한 서킷 브레이크 패턴
- 모니터링과 추적 패턴
- 중앙화된 로그 집계 패턴
- 서비스 매시(Service Mesh) 패턴
다양한 서비스 등록, 탐색 위한 Service registry , Service discovery 패턴
프론트 엔드(Front-End) 클라이언트가 여러 개의 백 엔드(Back-End) 마이크로서비스를 어떻게 호출해야 할까? 또한 스케일 아웃을 통해 여러 개로 증가됐다면 어떻게 적절히 부하를 분산할 수 있을까?
이를 위한 패턴이 서비스 디스커버리 패턴이다. 클라이언트가 여러 개의 마이크로서비스를 호출하기 위해서는 최적 경로를 찾아주는 라우팅 기능과 적절한 부하 분산을 위한 로드 밸런싱 기능이 제공되어 한다. 넷플릭스의 OSS로 예를 들면 라우팅기능은 줄(Zuul)이 로드밴런싱 기능은 리본(Ribbon)이 담당한다. 라우터는 최적 경로를 탐색하기 위해 서비스명칭에 해당되는 IP주소를 알아야한다. 그런데 이런 라우팅정보를 클라이언트가 가지고 있으면 클라우드 환경에서 동적으로 변경되는 백엔드의 유동IP정보를 매번 전송 받아 변경해야 한다. 따라서 제 3의 공간에서 이러한 정보를 관리해 주는 것이 좋다. 즉 백엔드 마이크로서비스 서비스 명칭과 유동적인 IP 정보를 매핑하여 보관할 저장소가 필요하다. 넷플릭스 OSS유레카(Eureka)가 그 기능을 담당하고 이런 패턴을 서비스 레지스트리 패턴이라 부른다.
아래 그림처럼 각각의 서비스 인스턴스가 로딩 될 때 자신의 서비스이름과 할당된 IP주소를 레지스트리 서비스에 등록한다. 그런 다음에 클라이언트가 해당 서비스명을 호출 시 라우터가 레지스트리 서비스를 검색해서 해당서비스이름과 매핑 된 IP정보를 확인 후 호출한다. 이 레지스트리 서비스는 모든 마이크로서비스의 인스턴스의 주소를 알고 있는 서비스 매핑 저장소가 된다. 모든 마이크로서비스가 처음 기동 될 때 자신의 위치 정보를 저장하고 서비스 종료 시 위치 정보는 삭제된다.
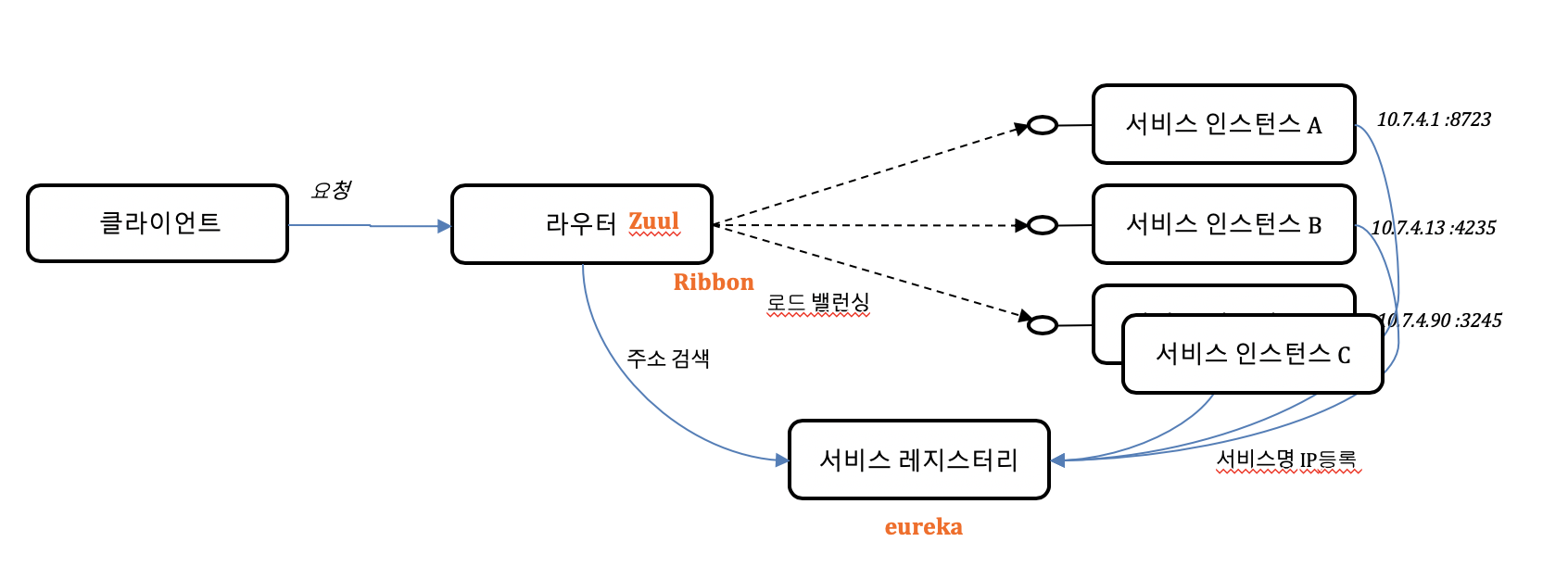
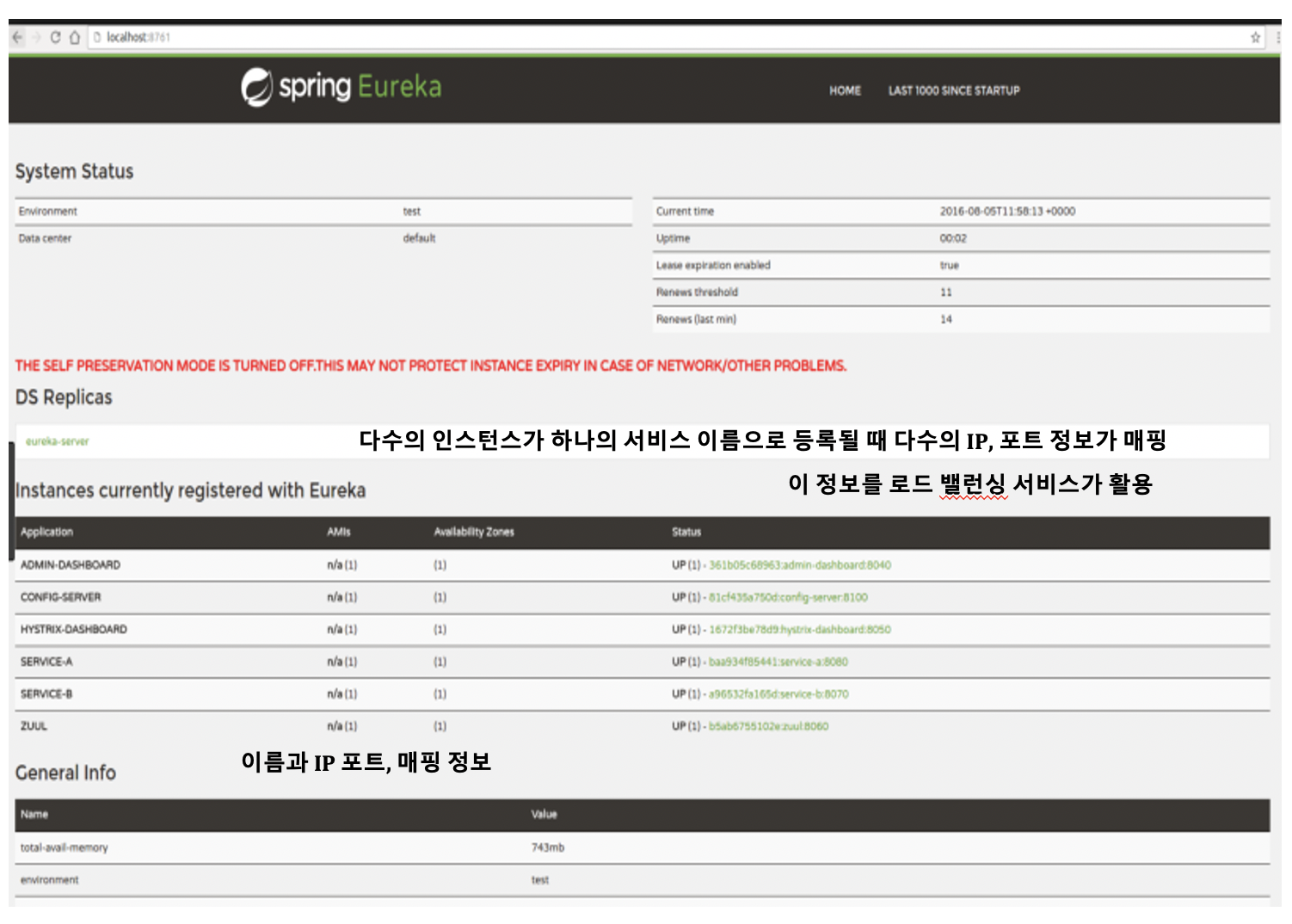
업무 처리를 위한 마이크로서비스뿐만 아니라 관리,운영을 위한 기반 서비스들의 주소도 같이 보관한다. 아래는 스프링 유레카로 레지스트리 서비스를 구현한 모습이다. 중간에 보면 서비스 이름과 IP 포트 정보가 매핑 된 것을 확인할 수 있다. 특히 다수의 인스턴스가 하나의 서비스 이름으로 등록될 때 다수의 IP, 포트 정보가 매핑 되고 라우터는 이 정보를 질의해서 로드 밸런싱 처리도 할 수 있다.
쿠버네이트 이런 서비스 디스커버리 기능을 자체 기능인 쿠버네티스 서비스(Kubernetes Service)로 제공한다.