
Introduce to Performance test(1/5)
Updated:
안녕하세요!
이번 글은 총 5개 시리즈로 성능테스트에 대해 포스팅을 하려 합니다.
포스트는 성능테스트 개요부터 계획/분석/설계/수행/보고까지 테스트 수행의 전반에 대한 내용으로 시리즈의 구성은 아래와 같습니다.
- 성능테스트 개요
- 사전점검 및 계획단계
- 분석 단계
- 설계 단계
- 실행 및 보고 단계
성능테스트 개요
1. 테스트 개요
테스팅의 범위에 속한 성능테스트, 기능테스트는 언제나 떼어놓을 수 없는 단짝입니다만 가깝고도 먼 관계이기도 합니다.

어떤 새로운 프로그램이 만들어지면 당연하게도 개발자는 프로그램에 대한 기능 테스트를 수행하게 됩니다. 디버깅 과정을 거치며 하기 싫어도 하게 되는 과정이죠. 물론 깊이의 차이는 있을 수 있습니다만 기능 테스트는 필수적으로 하게 됩니다. 반면 성능테스트는 어떨까요? 성능테스트는 시스템에 일정량의 부하를 발생시켰을 때 응답시간, 네트워크 사용량, 서버 용량, 데이터 처리량 등을 종합적으로 판단하여 최적의 성능을 발휘하기 위한 테스트입니다. 이를 위해 개발 프로그램과는 별도의 도구(ex. LoadRunner, Jmeter, SilkPerformer)를 통해 자동화 스크립트 작성 및 부하 생성을 진행해야 합니다. 중소규모의 프로젝트에서는 비용과 시간의 문제로 인해 성능테스트를 간과하는 경우가 많습니다. 이는 관리자의 성능테스트에 대한 오해와 얕은 지식에서 비롯할 수 있는데요 아는만큼 보인다고 하죠.

이는 결국 오픈 이후 장애로 연결되고 테스팅이 그러하듯 문제 발견이 늦어지면 늦어질수록 이를 해결하기 위한 비용은 기하급수적으로 증가하게됩니다.
1-1 테스트 발전 단계
테스팅은 아래와 같이 5단계로 발전되어 왔습니다.
1단계( ~1956) : The debugging-oriented period
2단계(1957~1978) : The demonstration-oriented period
3단계(1979~1982) : The destruction-oriented period
4단계(1983~1987) : The evaluation-oriented period
5단계(1988~ ) : The Prevention-oriented Period
1단계에서는 디버깅 위주의 시대는 테스트와 디버깅의 구분 없고, 테스팅은 버그 제거를 돕는 활동으로 인식되었습니다.
2단계에서는 증명 위주의 시대에 테스팅의 목적은 소프트웨어가 요구사항을 만족시키는지 보여주고 증명하는 것이었습니다. 이 시기에도 테스팅은 디버깅과 오류(faults)를 발견하고, 위치를 파악하고, 수정하는 과정에서 여전히 연계되어져 있었죠.
3단계는 파괴 위주의 시대는 테스팅을 오류를 발견하는 활동이라는데 초점을 맞췄습니다. 디버깅은 오류의 위치를 파악하고 수정하는 일련의 구별되는 활동으로 보았죠.
4단계는 평가 위주의 시대에 와서는 테스팅을 소프트웨어 개발 생명주기 (lifecycle)와 통합된 활동으로 보았습니다. 검토활동 (Review Activity)의 가치가 인식되었고, 테스팅의 개념이 확정되어 요구사항, 디자인, 임플리멘테이션 (implementation) 오류를 발견하는 활동을 포함하게 되었습니다.
5단계는 예방 위주의 시대는 CMM(Capability Maturity Model)과 TMM의 레벨5 최적화 단계를 그대로 반영했습니다. 이 시기의 주요 테스팅 목적은 요구사항, 디자인, 임플리멘테이션 (implementation) 오류를 예방하는 것입니다. 이처럼 테스팅의 범위가 넓게 정의되고 검토활동은 테스트 계획, 테스트 설계, 제품 평가를 지원합니다.
1-2 효과적인 테스트
테스트는 어디까지 하는것이 가장 효과적일까요? 최선은 결함율 0%인 프로그램이겠지만 이는 현실적으로 불가능합니다. 이때 Q-Cost를 따져보아 적정선에서 테스트를 마무리 해야 하는데요 먼저 Q-cost(품질비용)에 대해 알아볼 필요가 있습니다.
Q-cost는 요구된 품질(설계품질)을 실현하기 위한 원가로 정의할 수 있습니다. Q-cost는 경영자에게 품질문제를 비용문제로 전환하여 문제에 대한 경각심을 높이고 절감목표를 설정하여 적절한 대책과 개선 계획을 추진하도록 합니다. 궁극적인 목적은 품질향상과 원가절감에 있죠.
Q-cost의 일반적인 비용은 아래와 같습니다.
- 예방비용 5~10%, 평가비용 20~25%, 실패비용 65~75%
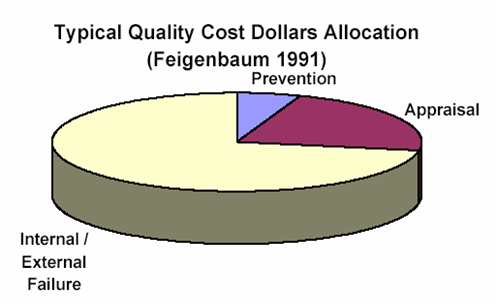
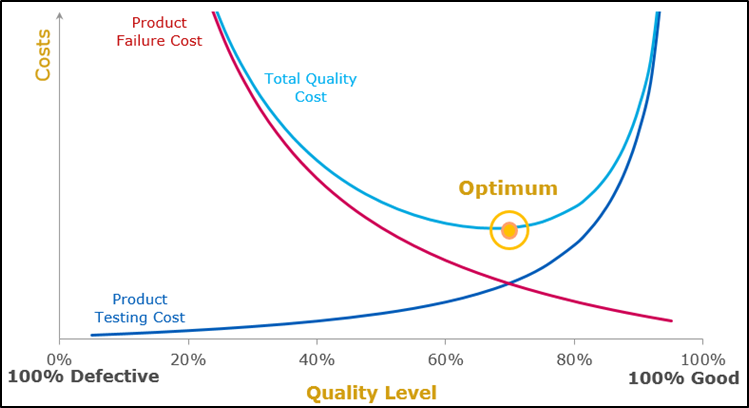
Q-cost는 초기에 결함을 발견하고 수정할수록 품질비용이 절약되는 것을 의미합니다. 하지만 결함을 완벽하게 발견하고 제거하는것은 현실적으로 불가능하므로 이를 위해 Cost Balancing을 맞출 필요가 있습니다. 적정 수준 이상의 결함 발견 행위는 비용대비 효과가 감소하게 됩니다. 과유불급(過猶不及)이죠. 아래 그림을 보면 Q-cost의 적정 시점을 보여줍니다.
기존(근래까지) 성능테스트는 보통 프로젝트 막마지에(통합테스트 단계)에 수행하였습니다. 막바지에는 결함 수정, 요구사항 변경 등 정신없이 바쁠 시기입니다. 이 시기와 겹쳐 성능테스트를 수행하다 보니 짧은 기간에 주요 화면에 대한 Sampling 테스트를 수행하게 되어 전체 화면에 대한 Coverage가 낮았습니다.
Microservice의 경우 POD의 개수가 많아 이에 대한 Coverage 또한 낮아지는 문제가 있죠.
최근 Software Modernization Trand에 따라 성능테스트 역시 Shift-left의 필요성이 대두되고 있습니다. 즉, Agile 환경內 성능테스트가 포함됨을 의미합니다.
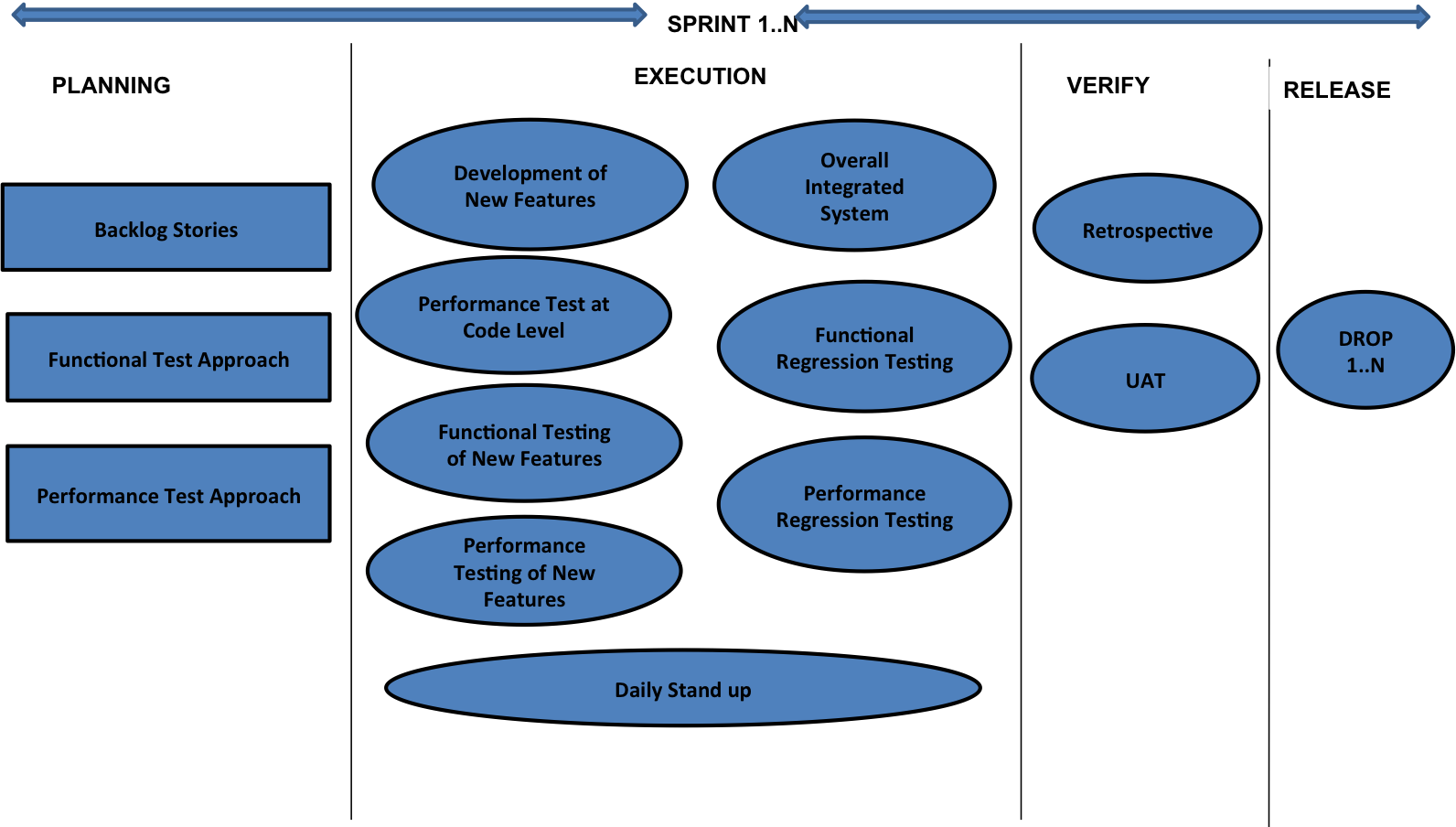
Agile 개발 주기내에 성능테스트가 포함되면 이미 개발 단계에서 단위 업무별 품질을 확보할 수 있으며 이후 스크립트를 재사용 하여 빠르고 강력한 통합 성능테스트를 수행할 수 있게 됩니다.
1-3 성능테스트 개요
성능테스트는 일반적으로 다음과 같은 목적을 가지고 수행하게 됩니다.
- 오픈 후 부하 상황에 대한 대비
- 고객과 합의한 성능 목표(기준)의 충족 여부 판단
- 다양한 사용 환경에 따른 시스템 최대 처리량 확인
- 주요 성능 병목/결함 조기 발견 및 해결
- 감리 및 검수 대응
- 시스템 성능 최적화
- 시스템 비용 최적화
그럼, 성능테스트란 뭘까요?
성능 테스트란 실제 Application으로 실제 환경 Infra 하에서,
실 세계의 부하량으로 모델링하여 성능을 측정하고, 용량 및 Transaction을 수용할 수 있는지 결정하기 위해 수행하는 행위입니다.
즉, 전체 시스템 관점에서 정의된 목표에 만족하는 지를 판단하고 프로그램과 모든 외부 접속 또는 커뮤니케이션의 정확성을 검증하는 비 기능 테스트의 종류입니다.
주로 명세 기반(Blackbox) 기법을 사용하며 독립적인 테스트 조직이 수행하는 경우가 많습니다. 이는 전문적 영역으로 툴에 대한 이해와 다양한 시스템에 대한 이해 및 아키텍처의 흐름의 분석을 통해 Workload를 산출하여 실 운영시의 부하를 재현할 수 있어야 하기 때문입니다.
1-4 기본용어 및 이론
성능테스트의 주요 기본용어 및 이론을 살펴보겠습니다. 기본 용어는 다음의 항목들의 의미에 대해, 이론은 Little’s law에 대해 알아보겠습니다.
- 응답시간
- 사용자
- TPS(Transaction Per Second)
- Little’s Law
- Throughput
1-4-1 응답시간
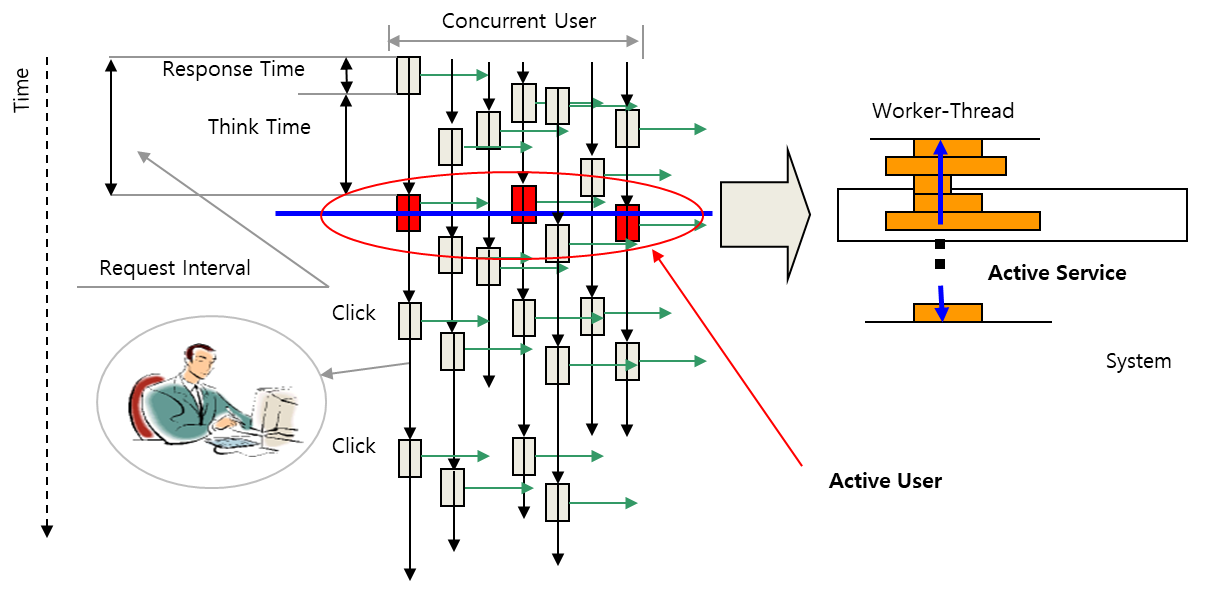
아래 이미지의 빨간색의 점은 사용자가 사이트에 접속하여 한 행위를 나타냅니다.
사용자는 시스템에 접속하여 로그인을 하고 페이지 컨텐츠를 검색, 수정, 삭제, 등록 등의 행위를 한 후 사이트를 빠져나오게 됩니다. 이렇게 접속한 후 페이지를 나가기까지의 시간을 Visit Time이라고 합니다.

다음의 그림은 Think Time과 Response Time을 나타냅니다.
사용자가 클릭을 한 후 결과가 단말까지 오는데 걸리는 시간을 Response Time(응답시간), 결과 내용을 본 후 다음 클릭을 할 때까지의 시간을 Think Time, 응답시간과 Think Time을 모두 포함한 시간을 Request Interval(요청 간격) 이라고 합니다.

여기서 Request Interval은 아래와 같이 계산될 수 있습니다.
\[\begin{matrix} \\ Request Interval(요청 간격) = Response Time(응답시간, 초) + Think Time(초) \\\\ \end{matrix}\]
1-4-2 Users
사용자는 총 사용자 중 접속사용자, 비 접속 사용자, 동시 사용자, 비 동시 사용자, 부하 사용자, 비 부하 사용자로 구분되며 다음 표와 같은 특성을 갖습니다.

| 구분 | 특성 |
|---|---|
| 총사용자(Named Users) | 시스템으로부터 접근 허가를 받은 총 사용자 |
| 접속사용자(Available Users) | 총사용자 중 현재 시스템에 로그 온 되어 있는 사용자 |
| 비접속사용자(Unavailable Users) | 총사용자 중 현재 시스템에 로그 온 되어 있지 않은 사용자 |
| 동시사용자(Concurrent Users) | 접속사용자 중 현재 시스템을 실제로 사용하고 있는 사용자로서 트랜잭션 발생 조건을 입력하고 있거나 결과물을 읽고 있는 사용자 트랜잭션을 발생하고 결과를 기다리고 있는 사용자 |
| 비동시사용자(idle Users) | 접속사용자 중 시스템을 실제로 사용하고 있지 않는 사용자 |
| 부하사용자(Active Users) | 동시사용자 중 트랜잭션을 발생하여 결과를 기다리고 있는 사용자 |
| 비부하사용자(Inactive Users) | 동시사용자 중 트랜잭션 발생 조건을 입력하고 있거나 결과를 읽고 있는 사용자 |
동시 사용자는 접속 사용자 중 현재 시스템을 실제로 사용하고 있는 사용자로서 트랜잭션 발생 조건을 입력하고 있거나 결과물을 읽고 있는 사용자로, 트랜잭션을 발생하고 결과를 기다리고 있는 사용자입니다.
아래 그림의 X축은 사용자, 점은 클릭 행위를 나타냅니다. 현재 시스템을 사용하는 동시 사용자는 트랜잭션을 발생시키고, 결과를 읽고 있는 사용자이므로 여기서 동시 사용자는 6명이 되겠네요.

부하 사용자는 아래와 같습니다.
동시사용자와 달리 동 시간대에 시스템에 부하를 발생시키는 사용자로 아래 그림에서는 3명이 부하 사용자로 확인됩니다.
1-4-3 TPS(Transaction Per Second)
TPS(Transaction Per Second)는 시스템의 주요 성능 Factor로 초당 발생하는 Business Transactions 건수를 의미합니다. cf) Page View, Dynamic Page 이는 곧 TPM(Transaction Per Minutes), TPH (Transaction Per Hours)로도 나타낼 수 있으며 1 TPS = 60 TPM = 3600 TPH 입니다. 즉, 단위시간당 서버가 처리할 수 있는 일의 한계를 나타내는 값으로, 사용량이 증가함에 따라 TPS도 증가하게 되며 병목이 발생하게 되면 이 수치도 더 이상 증가하지 않습니다.
예를 들면 아래 그림과 같이 분당 10갤런의 물(사용자 요청)이 수조에 떨어집니다. 이 수조는 총 1000갤런(서버의 처리가능 용량)의 물을 담을수 있고 수도를 통해 분당 10갤런(초당 처리량, TPS)의 물을 내보낼 수 있습니다. 그런데 내보내는 수량보다 들어오는 수량이 많게되면 수조는 언젠가 넘치게 되죠(응답시간 지연)

다음의 그래프는 TPS와 사용자 증가의 상관관계를 나타내는 그래프입니다.
사용자가 증가할수록 처리량도 같이 증가하지만 일정시점 이후 처리량이 더 이상 증가하지 않습니다. 이는 시스템의 자원 또는 병목 발생으로 인해 나타나는 현상이며 계속해서 고 부하가 지속되면 2차 병목이 발생되어 처리량이 오히려 감소하는 현상을 보입니다.

1-4-4 Little’s Law
Little’s Law는 MIT가 개설한 경영과학 과정에서 최초로 학위를 받은 존 리틀에 의해 만들어진 경제와 관련된 법칙으로 프로세스의 안정상태에서의 재고와 산출율 그리고 흐름 시간의 상관관계를 나타낸 법칙입니다. 리틀의 법칙의 유용한 점은 매우 단순한 수식이지만 어떤 시스템의 처리 용량을 알고자 할 때 큰 오차 없이 쉽게 계산할 수 있습니다. 간단하고도 유용한 공식이기 때문에 많은 곳에서 응용되는 공식으로 성능테스트에서도 이 공식을 사용할 수 있습니다.
다음의 그림은 TPS와 Response Time의 상관관계를 나타내는 그래프입니다. 사용자가 증가함에 따라 처리건수도 같이 증가하나 병목이 발생하여 더 이상 처리건수가 증가하지 않는 시점부터 응답시간이 지속적으로 증가하게 됩니다.
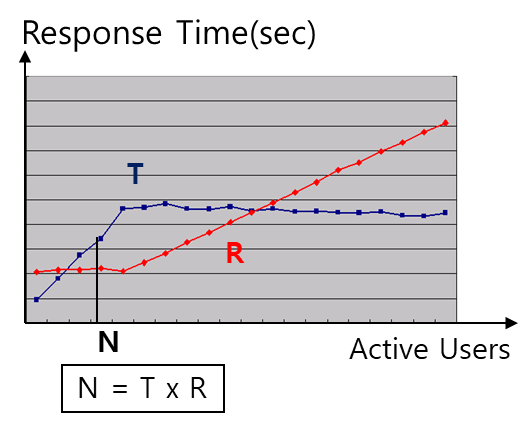
이를 계산식으로 표현하면 다음과 같습니다.
\[\begin{aligned} \\ {TPS} &=& \frac{부하사용자(Active Users)}{응답시간(Response Time)}\\ \\ &=& \frac{동시 사용자(ConcurrentUser)}{요청 간격(Request Interval)} \\ \\ \end{aligned}\]
또한 다음과 같이 동시사용자를 포함하여 계산할 수 있습니다.
\[\begin{matrix} \\ {Active Users} &=& {TPS} \mathsf{X} 응답시간(Response Time) \\ \\ &=& Concurrent Users \mathsf{X} \frac{응답시간(Response Time)} {요청 간격(Request Interval)} \\ \\ \end{matrix}\]
위 공식으로 보면 ThinkTime도 마찬가지로 구할 수 있습니다.
\[\begin{matrix} \\ ThinkTime = \frac {동시 사용자(Concurrent User)} {TPS(Transaction Per Second)} - 응답시간(Resp.Time(sec)) \\\\ \end{matrix}\]
또한, 성능테스트 시 Think Time과 같이 사용하는 Pacing의 개념을 알 필요가 있습니다. 아래 표와 이미지에 Think Time과 Pacing Time의 차이점을 설명하고 있습니다.
| 항목 | 내용 | 특징 |
|---|---|---|
| Think Time | 트랜잭션을 발생한 후 다음 동작을 수행하기까지의 대기시간 | 트랜잭션의 응답시간에 따라 TPS가 달라짐. 사용자의 패턴이 명확할 경우 유용함 |
| Pacing | 지정한 시간 이내에 트랜잭션이 완료되면 남은 시간을 대기, 지정시간 이상 지연되면 바로 다음 동작 수행 | 성능 목표를 TPS기준으로 산정하였을 때 정확한 TPS를 발생할 수 있음(단, 트랜잭션이 지정시간 이내로 들어올 경우) |
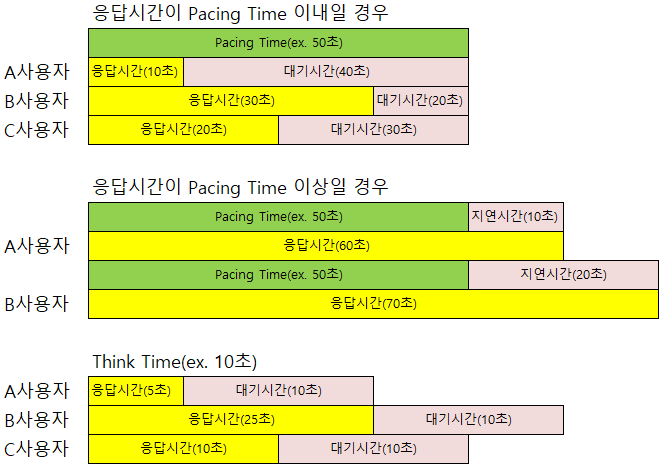
그렇기 때문에 성능테스트의 목표를 TPS로 선정하였다면 정확한 목표 TPS 측정을 위하여 Pacing Time을 적용하여 성능테스트를 수행해야 합니다. 반면 TPS가 아닌 동시유저를 기준으로 테스트를 수행한다면 Think Time을 적용하여 테스트를 수행해야 합니다.
\[\begin{matrix} \\ Pacing Time = \frac{부하 사용자(Active User)}{TPS} \\\\ \end{matrix}\]
Pacing Time을 이용한 테스트 수행 시 LoadRunner 또는 SilkPerformer등의 성능테스트 도구의 SLA(Service-Level Agreement) 기능을 통해 성능테스트의 성공/실패 여부를 바로 확인 할 수 있습니다.
끝마침
이로써 Introduce to Performance test의 첫 번째 포스팅을 마쳤습니다. 실제 성능테스트 수행 시 기술한 항목들을 근거로 계획, 분석, 설계, 수행, 보고의 단계를 거쳐 성능부하 테스트를 성공적으로 완료하게 됩니다. 다음 포스팅부터는 본격적인 성능테스트 절차 및 방법을 기술할 예정이므로 많은 관심 부탁드립니다.
감사합니다.