
Cloud 환경下의 성능부하테스트
Updated:
4차 산업혁명의 도래와 함께 Cloud로 전환되는 시스템이 근래들어 부쩍 늘었습니다. 이로 인해 시스템 성능/부하테스트를 하고있는 엔지니어는 중대한 도전에 직면하게 됩니다.
‘성능테스트? 이제 필요있나?’ ‘클라우드에서는 자동으로 확장되는데 뭐하러 돈 들여가며 테스트를해?’
On-Premise에서 Cloud로 전환되는 과정에서 성능테스터가 가장 많이 듣는 말이 아닌가 싶습니다. 이 말 그대로라면 더 이상 Cloud 환경에서는 테스트 엔지니어가 필요 없어진다는 말이 아닙니까!

그렇다면. 정말 이 말은 사실일까요?
아닙니다. 오히려 더욱더 성능테스트가 중요해졌습니다.
그렇다면 어째서 오히려 성능테스트가 더욱 중요해졌을까요?
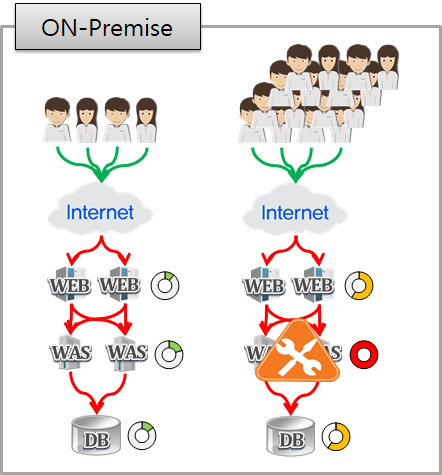
이 그림은 On-premise 환경에서 발생하는 장애 현상중 대표적인 장애를 나타내는 그림입니다. 사용자가 증가함에 따라 물리적 자원의 한계로 인해 더 이상 처리할 수 없는 상태가 되면서 장애가 발생하는 모습을 나타내고 있습니다.
우리는 이러한 환경에서 성능테스트를 통해 각 Tier 사이에서 발생하는 여러가지 병목현상과 자원 한계로 인해 발생하는 병목을 찾아 해결해 왔습니다.
그렇다면 Cloud에서는 어떨까요?
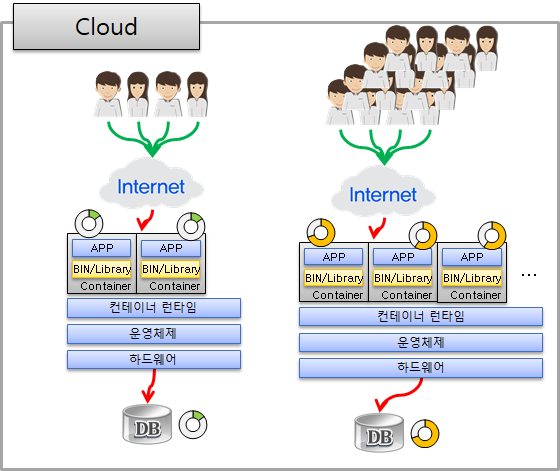
Cloud 환경에서는 부하가 증가함에 따라 WEB/WAS가 포함된 POD(Kubernetes에서의 애플리케이션 단일 인스턴스 를 의미함)이 자동으로 확장되면서 대량 부하 상황에서 자원 부족으로 인한 서비스 중지현상에 대응이 가능하죠.
다만 이는 POD와 소스가 최적화 되었을 때의 이야기입니다.
Cloud는 Published POD 이미지로 Auto-Scale을 합니다.
만약 이 Seed POD에 문제가 있다면 어떻게 될까요?

POD의 각 자원은 충분한 여유가 있지만 내부 문제(ex. Connection pool)로 인해 남은 자원을 활용하지 못한 채 서비스를 하고, 결국은 응답시간 지연 등의 현상이 발생하게 됩니다.
물론, Auto-Scaling 정책에 따라 현상은 달라질 수 있습니다.
CPU 기준으로만 Auto-Scaling을 설정했을 경우에는 Scale-out조차 발생하지 않은 채 서비스 장애가 발생하겠지요.
그러나 이 상태에서 Scale-out이 발생한다고 해도 여전히 같은 문제를 안고 가게 됩니다.
100의 일을 할 수 있는 POD가 10의 일만 한 상태에서 추가 POD만 계속 늘어나면(물론, Auto-scaling도 무한정 가능한 것은 아닙니다) 심각한 자원 낭비를 가져오게 되고, 이는 곧 비용과 직결되게 되는 것이죠.
그렇기 때문에 Seed가 되는 POD를 최적화 하여야만 Cloud를 온전히 사용할 수 있습니다.
또한 서비스가 MicroService화 되면서 On-premise에서 2~3개의 Instance로 서비스하던 형태에서 수십~수백개의 POD로 쪼개어 서비스를 하게 되었습니다. 이는 곧 최적화 해야 할 POD의 수가 많아지고 병목이 발생할 수 있는 구간 또한 증가하게 될 것입니다.

물론, MicroService의 장점은 많지만 엔지니어 입장에서는 많은 POD에 대한 최적화 및 성능 검증, 모니터링을 생각하면 머리가 지끈지끈해지죠.

Cloud 환경의 주요 성능 검증항목
자. 그럼 Cloud 성능 검증할 부분에 대해 살펴보겠습니다.
※ 참고로 아래 설정값은 CloudZ+Kubernete 환경하에 작성되었음
- AutoScaling (Scale-in / Scale-out)
- Deployment (Rolling update / BlueGreen update)
- Pod (Core, Memory, Optimize)
1. AutoScaling
AutoScaling은 Cloud의 대표적인 기능 중 하나로 부하 레벨에 따라 자원을 수평적으로 확장해 주는 기능입니다. 테스트 수행 시 Scale-out이 발생할 수 있을 정도의 부하를 부여한 상태에서 POD 실행시간을 고려해 AutoScaling 정책을 설정 하고 Liveness, Readiness 설정을 통해 적절한 시기에 정상적인 동작이 발생하도록 설정값을 조정할 필요가 있습니다. 설정값이 정상이라면 아래 이미지처럼 부하량 증가에 따라 POD의 증가/감소가 발생하게 됩니다.

Instance 실행 시간
Scale-out이 발생했다는 것은 부하량이 높은 상태이죠. 그렇기 때문에 새로운 POD가 실행되어 정상적인 서비스를 하기까지 현재의 POD가 부하를 감내해야 합니다.
그렇기 때문에 부하를 감내할 수 있는 자원적 여유가 있어야 하므로
POD 실행 시간이 수초 이내일 경우 Autoscaling 기준을 CPU 70%~ 80%로,
수분 이내일 경우 50%~60%로,
수십분 이내일 경우 50% 이하로(이 경우에는 POD 경량화가 필요합니다) 설정하는것이 좋습니다. 물론, 이는 상황에 따라 다른 설정이 필요할 수 있습니다.
Liveness Probe
상세 설명: Kubernetes Lessons Learned 시리즈 (1)
POD가 동작 중인지 여부를 나타내는 Probe입니다. 만약 활성 프로브(liveness probe)에 실패한다면 kubelet은 POD를 죽이고 해당 POD는 재시작 정책의 대상이 됩니다. 또한 POD가 활성 프로브를 제공하지 않는 경우 기본 상태는 Success입니다. 이 설정이 없을 경우 신규 POD가 생성 되자마자 Kill되어 Scale-out에 실패하게 됩니다.
Readiness Probe
상세 설명: Kubernetes Lessons Learned 시리즈 (2)
POD가 요청을 처리할 준비가 되었는지 여부를 나타내는 Probe입니다. 만약 readiness probe가 실패한다면 엔드포인트 컨트롤러는 파드에 연관된 모든 서비스들의 엔드포인트에서 Instance의 IP주소를 제거합니다. readiness Probe 초기 지연 이전의 기본 상태는 Failure이며 만약 POD가 readiness Probe를 지원하지 않는다면 기본 상태는 Success입니다.
이를 종합하여 볼때 K8S의 yaml에 아래와 같은 설정이 필요합니다.
spec:
containers:
- name: ...
image: ...
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 100
timeoutSeconds: 15
livenessProbe:
httpGet:
path: /liveness
port: 8080
initialDelaySeconds: 100
timeoutSeconds: 15
주요하게 살펴볼 항목값은 아래와 같습니다.
-
InitialDelaySecondsInstance가 생성된 후 여기 설정한 시간 만큼 대기합니다. 정상적으로 서비스 되기까지의 대략적인 시간(초)으로 설정해야 하며, 기본값은 0초, 최소값은 0초 입니다. -
PeriodSecondsProbe 실행(상태체크) 주기입니다. 기본값은 10초, 최소값은 1초입니다. 이 값이 너무 낮다면 체크 주기와 횟수가 빨라져 체크 실패를, 너무 높다면 신규 POD 서비스 시간이 지연됩니다.
2. Deployment
Cloud의 또다른 장점인 무 중단 배포시에도 성능테스트가 필요합니다.
무 중단 배포에는 두가지 방식이 있는데 실행된 POD와 동일한 개수로 Deploy한 후 기존 POD를 중단하는 Blue-green Update와 한번에 정해진 개수만큼 단계적으로 Deploy하는 Rolling update 가 있습니다.
Blue-green update

Blue-green update가 정상적으로 설정되었다면 아래와 같이 신규 POD로 한번에 서비스가 이전됩니다.
Blue-green update는 동 시간대에 모든 유저가 새로운 버전의 소스를 사용할 수 있는 장점이 있습니다만 운영중인 POD 개수 만큼 생성해야 하기 때문에 여유 자원이 없으면 운영이 어렵습니다.
Rolling update
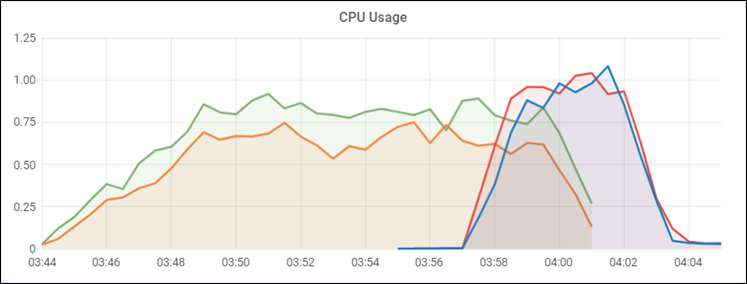
아래 이미지는 Rolling update 개념 그림입니다. Blue-green update와 다르게 하나씩 생성/삭제되는 방식입니다.
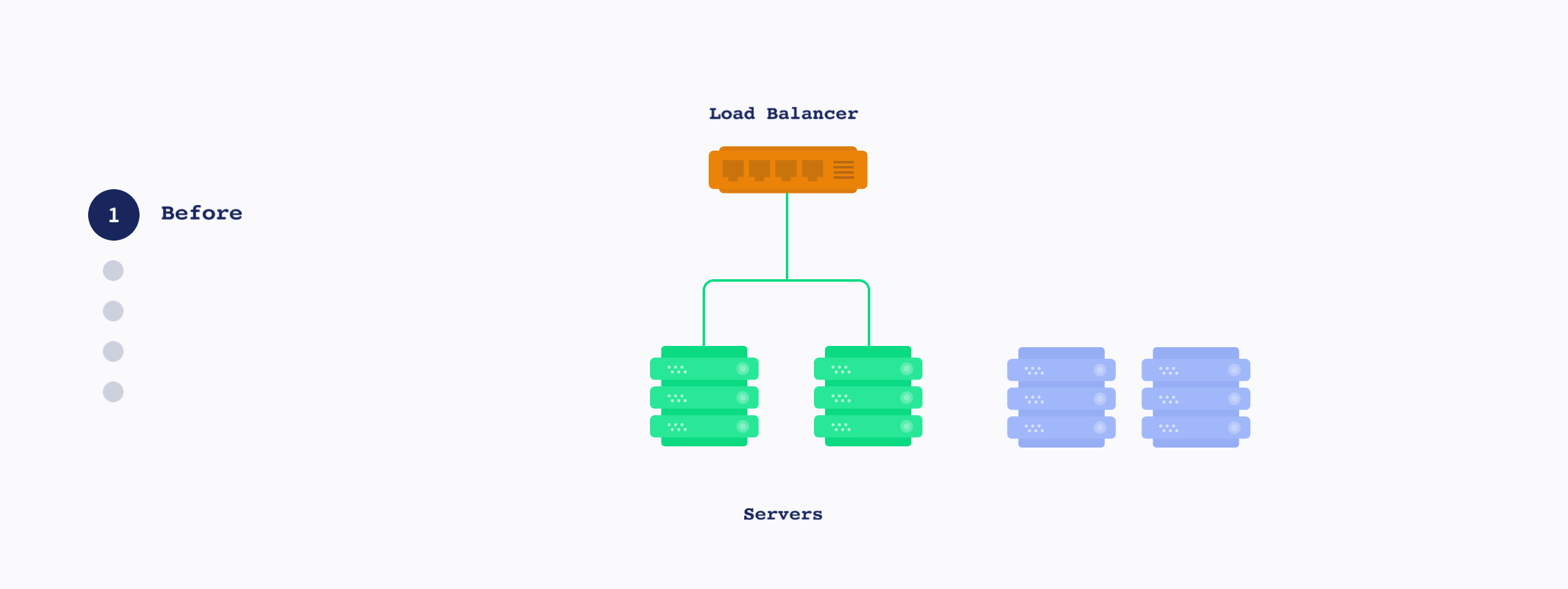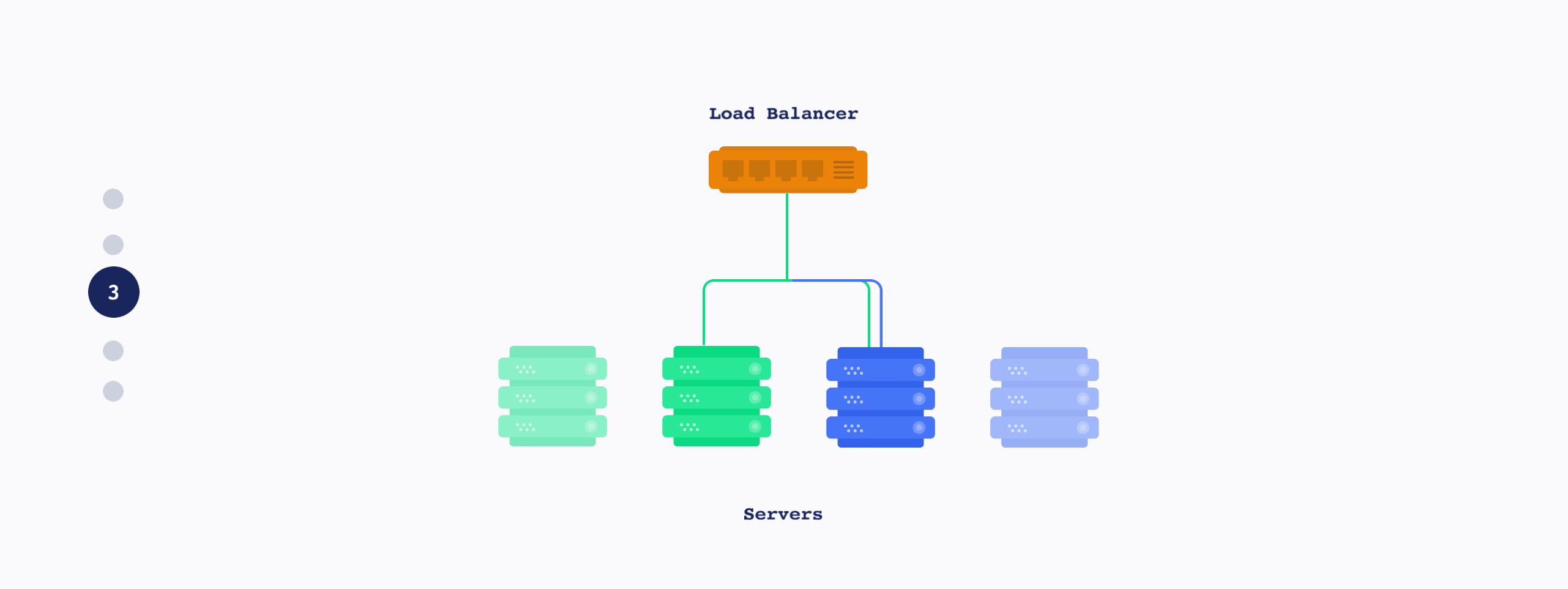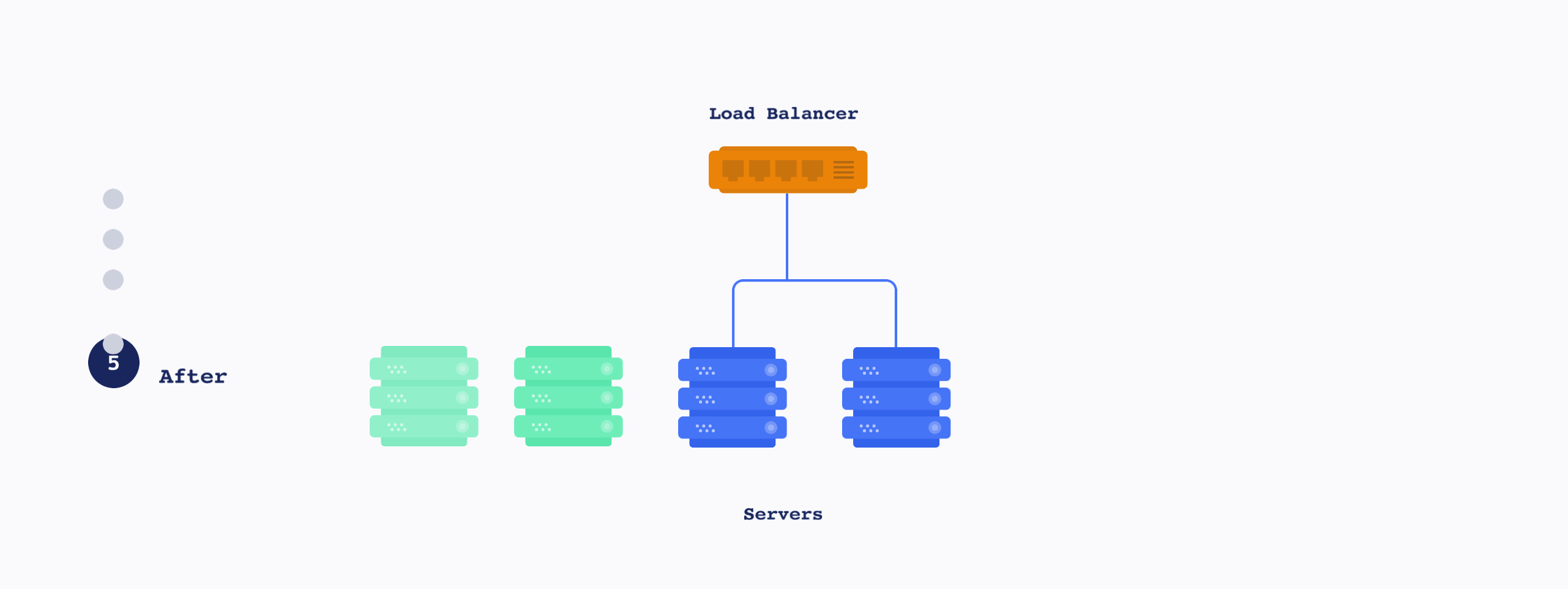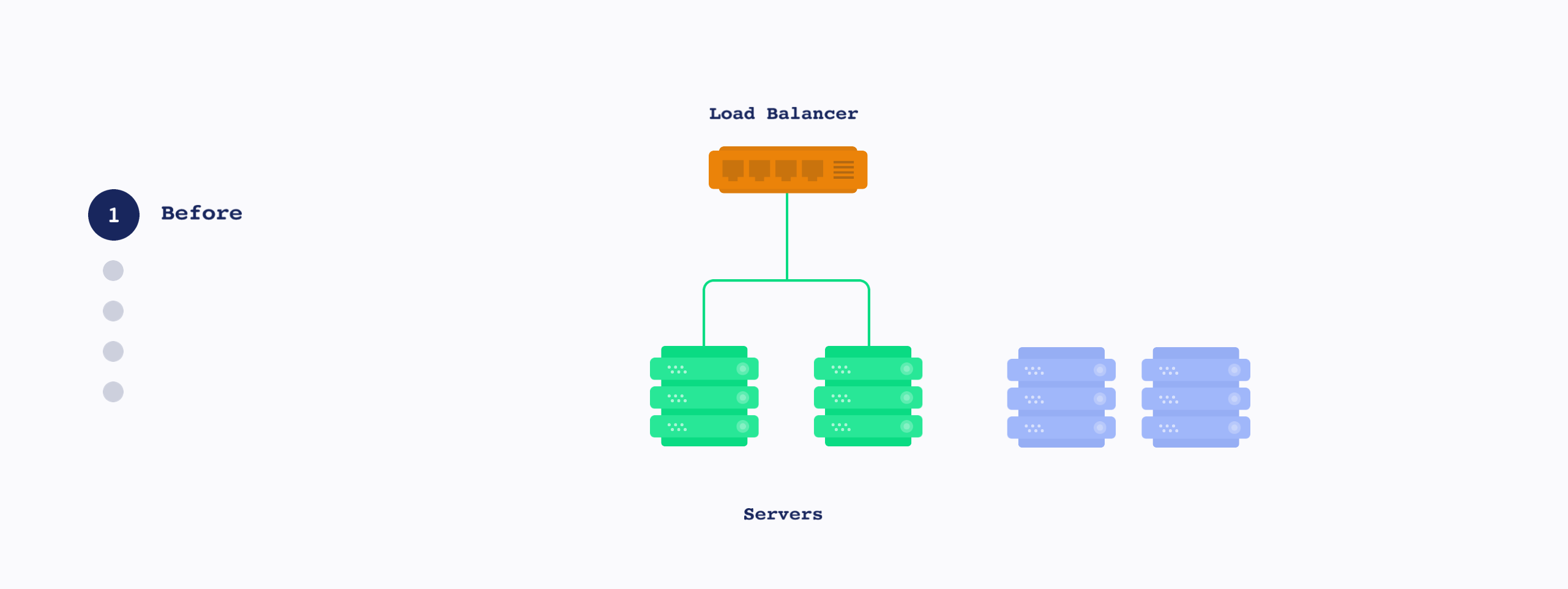
Rolling-update 수행 시 CPU 상황을 보면 CPU가 하나씩 순차적으로 생성/삭제 되는것을 볼 수 있습니다.(Time Scale 관계로 간격이 조금 적습니다만…)

Rolling update는 지정한 POD 개수씩 POD을 추가 및 기존 POD 제거를 하기 때문에 동 시간대에 유저들은 서로 다른 버전의 소스를 사용하게 됩니다. 다만 지정 POD 개수만큼의 여유만 있어도 배포가 가능하여 자원 이용이 용이합니다.
주요한 옵션 항목은 다음과 같습니다.
-
maxUnavaliableRolling-update중 동시에 삭제할 수 있는 POD의 최대 개수로 기본값은 replicas의 25%이나 안정성을 고려해1로 설정하여 POD를 하나씩 교체하는것이 좋습니다. -
maxSurgeRolling-update중 동시 생성하는 POD 개수로 기본값은 Replicas의 25%입니다1로 설정할 것을 권고합니다.
이를 고려하였을 때 K8S의 yaml은 아래와 같이 설정합니다.
spec:
replicas: 4
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
3. POD 최적화
설계 단계에서 POD에 할당되는 자원(CPU, Memory)은 대부분 추정에 의해 할당하게 됩니다. Microservice의 경우 수 많은 POD을 구성하면서 각 POD에 최적화된 자원을 할당하기란 사실 불가능하기 때문에 대개 일률적으로 자원을 편성하게 됩니다. 그렇기 때문에 성능테스트를 통해 POD의 설정값 최적화 및 적절한 자원의 배분이 아주 중요한 요소가 되었죠. 일부 POD은 특정 시점에 사용량이 급증하거나 또는 항시 자원 사용률이 낮을 수 있으므로 성능테스트 시 이를 고려하여 대상업무를 선정하고 부하를 산정할 필요가 있습니다. 아래는 성능테스트를 통해 POD별 자원 최적화 사례입니다.

또한, POD 최적화를 위해 다음의 Configuration을 사전에 확인하여 적용할 필요가 있습니다. 물론 성능테스트를 통해 아래 항목 이외에 추가로 튜닝할 항목들이 있으니 상황에 따라 더 많은 항목의 튜닝이 필요할 수 있습니다.
| 항목 | 기본값 | 최적값 | 항목정의 |
|---|---|---|---|
| Open Files | 1024 | 65535 | 한 프로세스에서 열 수 있는 최대 파일 수 |
| Max User Processes | 1024 | 65535 | 단일 유저가 사용 가능한 프로세스 최대 개수 |
| User Task Max | 1024 | Infinity | 사용 가능한 작업 개수 제한치 |
| vm.max_map_count | 65536 | 131072 | 사용할 수 있는 Memory Map 최대 개수 |
| Connection Pool | ? | 최적화 | POD와 DB간 연결 Pool 수 |
| LogLevel | Debug | Info | 시스템 로그레벨 |
끝마침
여기까지 Cloud 환경에서 알아야 할 성능테스트 요소들을 살펴보았습니다. Cloud가 처음 도입되었을 당시에 Cloud의 장점을 보았을 때는 성능테스트의 필요성이 점점 사라지는것 같아 보였으나 막상 뚜껑을 열어보니 오히려 더욱 더 중요한 요소가 되었습니다.
이후의 글에서는 사이트별 사례에 따른 테스트 수행 시나리오 및 방법, 튜닝요소에 대해 알아보겠습니다.
감사합니다.