
Chaos Engineering 개요
Updated:
기존의 전통적인 비즈니스 모델과 정체성에서 탈피하여 디지털 기업으로 탈바꿈하고자 하는 국내외 기업들이 점차 증가하면서, 기업 내부의 주요 시스템 및 대외 서비스들은 점진적으로 클라우드로 전환되는 추세가 가속화되고 있습니다. 이에 따라, 클라우드 서비스의 장애로 인해 유발될 수 있는 그 피해 규모와 파급력 또한 점차 커지고 있는 것이 사실이며, 사전에 효과적인 점검 체계를 갖추어 장애를 예방할 수 있도록 하는 것은, 기업에서 더이상 선택이 아닌 필수 요건이 되어가고 있습니다.
1. AWS의 국내외 장애 사례
클라우드 시장에서 부동의 1위를 지키고 있는 AWS의 장애와 관련된 국내 사례로는, 지난 2018년 11월 22일에 AWS 한국 데이터센터에서 발생한 DNS 장애를 예로 들 수 있습니다. 최초 DNS 오류(DNS resolution issues)가 발생한 이후, 그 장애가 점차 Amazon API Gateway, Amazon Kinesis Firehose, Amazon MQ, AWS IoT 등으로 확대되었습니다. 국내 고객사 일부(ex. 배달의민족, 쿠팡, 야놀자, 여기어때, 마켓컬리 등)에서는, 오전 9시부터 약 2시간 가량 ‘502 Bad Gateway’라는 문구 등과 함께 서비스에 대한 정상적인 이용이 불가능한 피해를 입게 되었습니다.
해외 사례로는 유명한 대규모 AWS 장애가 있었는데, 2011년 4월 21일 오후 12시 04분 부터 발생되었던 버지니아주 북부 데이터센터(AWS US-East)의 장애입니다. AWS를 이용하고 있는 여러 주요 서비스(ex. Quora, Reddit, HootSuite, Foursquare 등)의 중단 및 오류를 발생시켰으며, 4월 24일까지 지속되었던 미국 동부 지역의 Amazon EC2 및 Amazon RDS 서비스 중단 상황은, AWS에서 사후분석 및 공식적인 사과문을 게시하는 것으로 마무리 되었습니다.
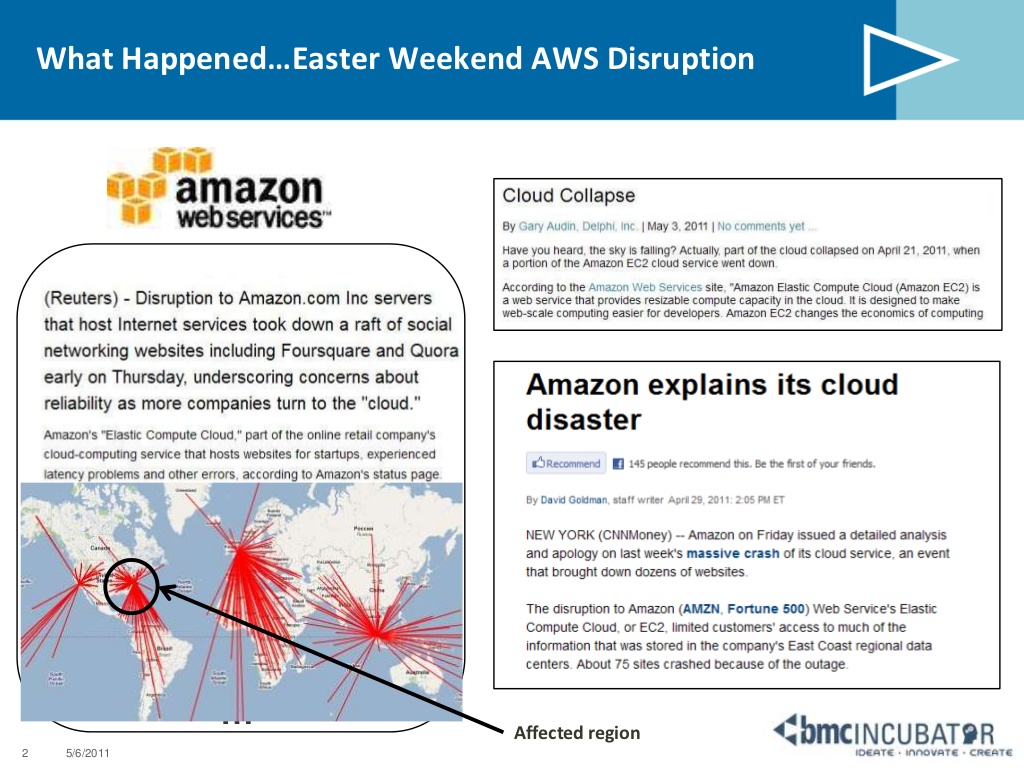
그림 1. Amazon Cloud Failure
Source: Amazon Cloud Disruption
2. 실패를 피하는 가장 좋은 방법
AWS의 대표적인 고객 중 하나인 Netflix는 2008년 8월에 시작한 클라우드 마이그레이션의 여정을 2016년 1월초까지 총 7년간에 걸쳐 완료하였으며, 이 시점부터 전세계에 분산된 여러개의 클라우드 지역을 기반으로 130개 이상의 국가를 대상으로 하는 서비스의 확장 제공이 가능해졌습니다.
처음 구축되었던 Netflix의 스트리밍 서비스는 Microsoft S/W 기반이었으며, 자체 데이터센터에서 운영되었습니다. 그러나, 2008년 8월 심각한 데이터베이스 손상으로 3일간 DVD 배송이 지연되는 문제를 겪은 후, ‘Single Points of Failure’에서 벗어나 수평 확장이 가능한 클라우드 내 분산시스템으로 이전하기 위해, AWS를 클라우드 제공업체로 선정하고 마이그레이션을 수행하였습니다.
Netflix는 안정적인 서비스 제공을 위해, AWS에만 의존하지 않고 자체적으로 ‘Chaos Engineering’ 기술을 도입하였습니다. 이를 통해, 예기치 않은 상황에서도 적기 대응이 가능하도록, 클라우드 기반 아키텍처에 탄력성을 구축하는 지속적인 노력을 기울였습니다. 그 결과, 위에서 언급한 2011년 대규모 AWS 중단 상황에서도 Netflix 홀로 영향을 받지 않고 정상적인 서비스를 제공할 수 있었던 사실은 현재까지도 유명한 일화로 남아 있습니다.
“실패를 피하는 가장 좋은 방법은, 끊임없이 실패하는 것이다.(The best way to avoid failure is to fail constantly)”라는 교훈을 열심히 실천하고 있는 Netflix가 만든 Chaos Engineering은 어떤 모습인지 살펴봄으로써, 장애 상황으로부터 자유로울 수 있게 했던 그 역량 구조에 대해 살펴 보도록 하겠습니다.
3. Chaos Engineering과 Testing의 차이
우선, Chaos 커뮤니티의 웹사이트에는 Chaos Engineering이 의미하는 바에 대해 다음과 같이 설명하고 있습니다.
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
Source: https://principlesofchaos.org/
Chaos Engineering이라는 용어를 이해하기 전에, 먼저 테스트의 중요성에 대해 알아 둘 필요가 있습니다. 우리가 테스트 관련 기술동향을 통해 반복적으로 확인한 바와 같이, Agile 개발환경 및 빈번한 배포가 일어나는 환경에서 사용자에게 원활한 서비스 경험을 제공하기 위해서는, S/W에 대한 지속적인 테스트가 필수적입니다. 이를 위해, 전사 품질 조직들은 철저하고 완전한 테스트가 가능하도록, 현대적이고 자동화된 방법으로 S/W 테스트 체계를 구현하여 지원하고 있는 추세입니다.
하지만, 점점 더 복잡해져가고 있는 최신 기술의 적용 및 클라우드 인프라 환경하에서는, 기존 테스트의 관점으로만 모든 이슈들을 사전에 파악하기에는 어려운 상황이 되어가고 있습니다. 이러한 문제점들을 먼저 겪었던 Netflix에서 기존의 단위, 기능, 인프라 테스트를 좀 더 효과적으로 수행하기 위해 소개한 개념들 중 하나가 바로 Chaos Engineering입니다.
이해를 돕기 위해, DevOps 엔지니어인 Cloud Freak이 말하는 ‘Chaos Engineering과 Testing의 차이점’에 대해 간단히 살펴보겠습니다.
테스트의 첫번째 개념은 기대되는 시스템 동작을 얻기위한 여러개의 입력값과 예상되는 출력값이 있다는 것입니다. 이것은 범위가 제한적일 수 밖에 없는데, 무언가 잘못되었을 때 시스템이 어떻게 행동하는지와 같은 완전히 새로운 지식에 대해서는 생성하지 못하기 때문입니다.
Chaos engineering은 시스템의 행동, 속성 및 성능에 대한 새로운 지식을 생성하는, 폭넓고, 주의깊으며, 예측 불가한 실험을 수행합니다. 다양한 연구형식에 기반하여 시스템을 매우 밀접하게 관찰하기 위해, 보다 넓은 범위와 계획되지 않은 조합을 가지고 수행합니다.
우리는 단위테스트를 설계할 때, 개별 컴포넌트 별로 예상되는 동작을 확인하는 테스트 케이스를 작성하고 테스트를 수행합니다. 단위 테스트가 종료되면, 통합 테스트를 수행하게 되는데, 컴포넌트들 간의 상호작용 및 서비스 레벨에서의 컴포넌트들간 상호작용을 테스트하게 됩니다.
Chaos Experiments는 외관상 테스트와 유사해 보입니다. 기존 테스트와 다른 점은, 클라우드 기반 분산 시스템에 문제를 발생시키기 위한 목적으로 Failure 및 Latency 상황 등을 만든다는 점이고, 시스템이 비정상적인 조건에서 어떻게 행동하는지 확인함으로써, 예상치 못한 장애를 쉽게 견딜 수 있도록 시스템을 변경하는 작업이라는 점에서 그 차이가 있습니다.
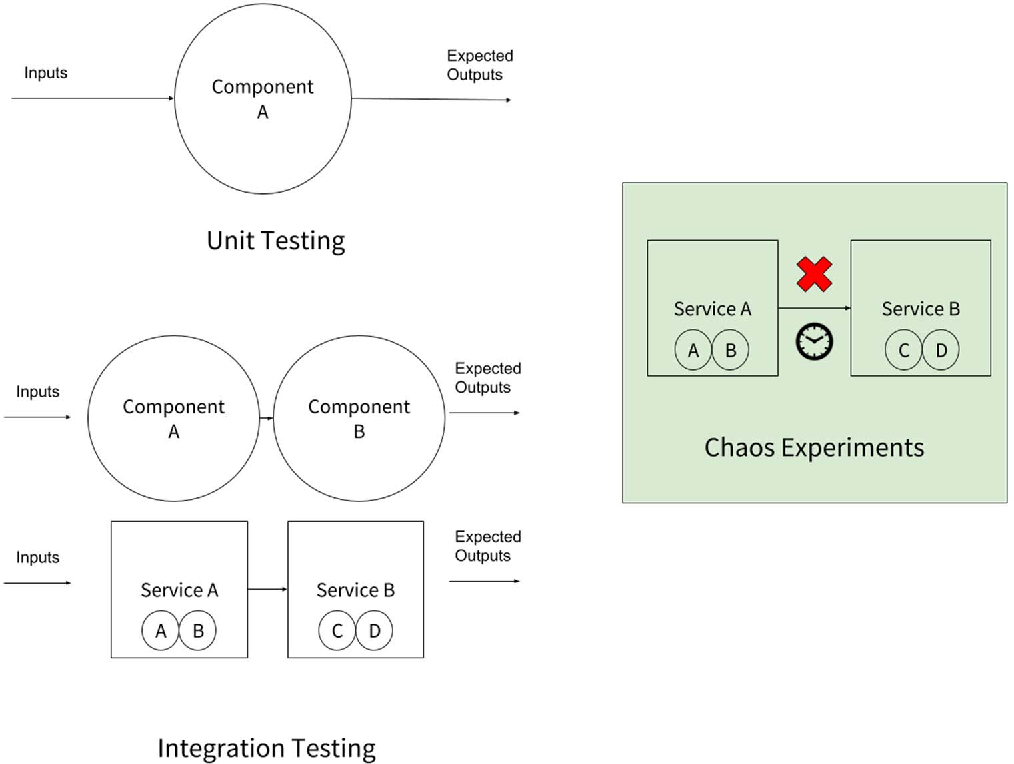
그림 2. Unit Testing, Integration Testing, and Chaos Experiments
Source: The Business Case for Chaos Engineering
4. Chaos Engineering의 시작 - Chaos Monkey
Netflix의 Greg Orzell은 2011년 클라우드 마이그레이션의 감독을 진행하면서 다음과 같은 아이디어를 생각해냈습니다. 상용환경에 장애를 일으킬 수 있는 도구를 만들어서, 취약점이 시스템 전체의 비정상적인 행동으로 나타나기 전 미리 식별하고 개선하면 좋겠다라는 것이었습니다. 그 아이디어는 현실로 이어져서, 서버를 무작위로 선택하고 일과시간에 상용서버를 비활성화할 수 있는 프로그램인 Chaos Monkey를 만들어 냈습니다.
“Chaos Monkey is a tool that randomly disables our production instances to make sure we can survive this common type of failure without any customer impact.”
Source: Netflix Technology Blog
Netflix는 기존의 물리적인 데이터센터 환경과는 달리, 클라우드 환경으로 이동하면서 시스템이 분산되어 있기 때문에 더 많은 장애가 발생할 수 있다고 가정하였습니다. 이러한 관점에서 Netflix는 자체 아키텍처 내에서 인스턴스 및 서비스의 임의종료를 통해 장애를 발생시킴으로써, 시스템의 안정성을 확인할 수 있도록 Chaos Monkey에 설계를 반영했습니다. Netflix는 Chaos Monkey 도구를 사용하는 이유에 대해 다음과 같이 설명하고 있습니다.
클라우드는 다중화(Redundancy) 및 장애허용(Fault-tolerance)에 관한 것입니다. 단일 컴포넌트가 100% 가동시간을 보장할 수 없기 때문에(그리고, 가장 비싼 하드웨어 조차도 결국 실패하기 때문에), 전체 시스템의 가용성에 영향을 주지 않으면서 개별 컴포넌트에서만 장애가 발생할 수 있도록 ‘아키텍처를 설계’ 해야 합니다.
우리는 우리의 가장 약한 고리보다 더 강해야만 합니다.
(We have to be stronger than our weakest link.)
Source: Netflix Technology Blog
5. Chaos Engineering의 구성
앞서 살펴 본 바와 같이, Chaos Engineering의 핵심 아이디어는 상용환경에서 장애가 발생하여 시스템이 중단될 때까지 기다리는 대신, 선제적으로 장애를 주입해 봄으로써 재난을 미리 대비하는 것입니다. Chaos Engineering은 시스템의 약점을 쉽게 발견할 수 있도록 도와주는 실험(Experiments)으로 생각할 수 있으며, 이 실험은 다음 4단계로 구성됩니다.
‘정상상태(Stady State)를 정의함으로써, 시스템의 측정 가능한 정상 동작의 기준(ex. Overall Throughput, Error Rates, Latency 등)을 설정합니다.
실험그룹(Experimental Group)과 대조그룹(Control Group)에서 “정상상태”가 계속될 것이라고 가설을 세웁니다.
서버중단, 하드 드라이브 오작동, 네트워크 연결 중단 등과 같은 실환경 상황을 반영하는 변수들을 도입합니다.
대조그룹과 실험그룹 사이의 차이점을 확인해 가설이 틀렸음을 입증합니다.
정상상태를 방해하는 것이 어려울수록, 우리 시스템에 대한 신뢰도는 더욱 높아지게 됩니다. 만약, 약점이 발견되었다면, 장애가 시스템 전반에 나타나기 전에 개선해야 할 목표가 생겼다는 것을 의미합니다.
Source: https://principlesofchaos.org/
6. Chaos Engineering 도입 사례 - Target
마지막으로, Netflix 외의 Chaos Engineering 도입 사례를 살펴봄으로써 이번 개요 글을 마무리하고자 합니다. 우리가 살펴볼 ‘타겟(Target)’은 미국의 대형 유통 체인으로, 지난 2016년부터 이커머스 강화를 위해 자사 온라인 사이트인 Target.com을 대상으로 Chaos Engineering을 도입하였습니다.
Target 팀 구성원들은 먼저 플랫폼의 오류 패턴을 식별하고 가장 심각한 장애유형들을 알려주는 ‘Telemetry Framework’을 구축했습니다. 또한, 팀의 어떤 엔지니어라도 문제를 해결할 수 있도록 ‘Playbooks’ 및 ‘Escalation Polices’를 만들었습니다.
Chaos Experiment 적용을 통해 발견한 사항들
Target 팀은 첫번째 수행한 Chaos 테스트를 통해, 복잡한 시스템에서 애플리케이션과 인프라가 실패할 수 있는 방식을 좀 더 명확하게 이해하는데 도움을 얻었습니다. 또한, 테스트에 참여하는 범위를 넓혀 애플리케이션 팀들도 함께 관찰하고, 영향도를 보고하고, 개선에 도움을 주게 되었습니다. 이를 통해, 탄력성의 원칙(Resiliency Principles)을 사고방식의 전면에 놓게 되었고, 시스템을 설계하고 개발하는 방식의 근본적인 전환을 가져오게 되었습니다.
Chaos Experiment 준비 방법
Target팀은 실험에 대한 사전준비를 위해 다음과 같은 ‘Chaos Experiment Form’을 만들어 사용함으로써, 실험 목적에 맞게 사전에 준비가 가능하도록 지원하였습니다.

그림 3. Chaos Experiment Form
항목별 설명
- Attack Type - 실행할 Chaos 실험(CPU, Memory, Network Latency 등)
- Duration of the Attack - 실험을 실행하는데 걸리는 시간
- Scope of the Attack - One Instance 또는 Entire Cluster of Instances
- Environment - Local, Test, 또는 Production
- Load - 실험 중 애플리케이션 실행을 위한 부하(Simulated, Synthetic, 또는 Actual User Data)
- Observability - 실험 참여 팀에게 발생현황을 알리기 위한 the Telemetry Setup (Alerting, Metrics 및 Reporting)
- Hypothesis - 실험중 그리고 결과로 예상되는 영향, 행동 및 장애에 대한 가설
- Results - 실험의 실제 영향, 행동 및 장애
- Action Items - 실험 종료 후 팀이 수행해야 할 작업들(ex. 다른 제약조건으로 재실험, 원격 분석 추가, 애플리케이션 결함 수정 등)
Source: Target Tech Blog
실험 당일 수행결과, 그리고 얻게된 것들
이 실험에서, Target팀은 프록시 서버가 대기시간을 처리하기 위해 auto-scaled되는 것을 확인하였습니다. 100m/sec의 다음 실험 세트인 500m/sec 및 1,000m/sec에서도 프록시 서버는 증가된 대기 시간을 처리하는 것으로 나타났습니다. 한편, 실험을 통해 영향을 받게 된 서버 지연 현상에 따라, 예상치 못한 성능 동작에 의해 부하발생기(the synthetic load generator)와 측정지표 기록이 모두 영향을 받기 시작했습니다.
이 실험 중에 Target팀은 프록시 서버를 정상 상태로 복원하는 방법을 설명하는 ‘Playbooks’의 지침에 따라 각 실험 후 서비스를 복원하였습니다. 이 실험을 통해, Target팀은 여전히 수많은 애플리케이션 동작에 대해 학습이 필요하다는 점과 함께, 다음 실험 전에 수정이 필요한 사항들에 대한 결과를 얻을 수 있었습니다.
이상으로, Chaos Engineering이 나오게 된 배경과 기본적인 개념, 그리고 적용 사례에 대해 간략히 살펴보았습니다. 참고로, 이번 글에서는 다루지 않았지만, Chaos Engineeing과 관련된 자동화 도구로는 Gremlin, Litmus Chaos, Chaos Toolkit 등을 포함한 다양한 상용 및 오픈소스 도구들이 현재 제공중에 있으며, 상세 내용은 링크된 각 사이트를 통해 참조하시기 바랍니다.
[END]
참고 글