
2020 State of Performance Engineering report: (4) Building in performance engineering
Updated:
Chapter 4: Building in performance engineering
이번 Chapter에서는, 제약된 환경에서 운영되는 Engineering팀이 Application Delivery Pipeline의 효율성을 극대화하기 위해, 다른 활동들과 Performance Engineering 활동을 어떻게 통합하는지에 대해 살펴보려고 합니다. 목표는 문화적으로 기여하고, 자동화를 통해 개발주기를 최소화하며, Orchestration을 통해 정확성을 증가시키고자 하는 핵심 요구사항을 준수하면서도, 최적화와 혁신을 동시에 이룰 수 있는 기술적인 방법들을 식별하는 것입니다.
Continuous Testing은 요구사항을 수집하는 것으로부터 상용화에 이르기까지, 전체 애플리케이션 개발주기에 걸친 지속적인 테스트 사례(the ongoing practice of testing)입니다. Continuous Testing이 제공하는 이점에는 보다 빠른 피드백, 더 나은 테스트 커버리지, 더 많은 개발자가 참여하는 테스팅 등이 포함됩니다. 주요 초점은, 비즈니스 가치가 예상대로 달성되는 것을 보장하는 동안, 예상치 못한 동작이 발생하는 경우 즉시 이를 발견하고 수정하는 것입니다.
Embedding performance engineering into continuous testing
배포 파이프라인을 최적화하기 위해서는, Performance Engineering Process를 통해 병목현상과 비효율성을 제거해야 합니다. 아래 그림은 Continuous Testing Pipeline의 예를 보여줍니다.
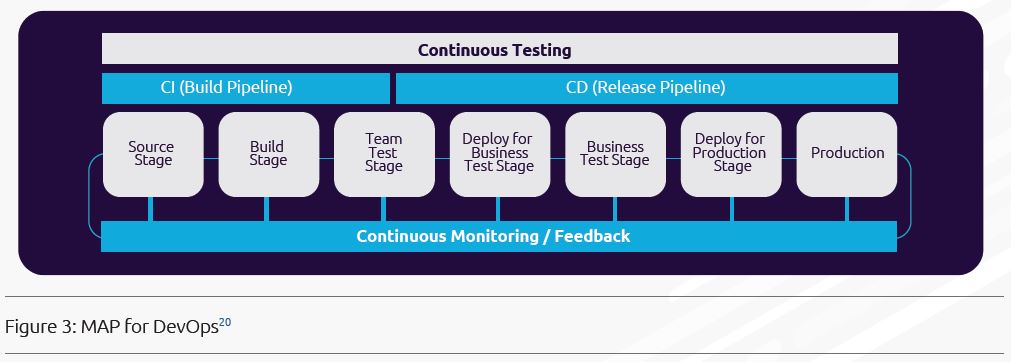
자동화 도구는 프로세스를 자동화하고, 대기시간을 감소시키고, 수작업 오류를 감소시킬 수 있습니다. 그러나, 통합되지 않은 상태의 자동화 도구는 또한 복잡성과 비효율성을 증가시킬 수 있습니다. 방법론, 활동, 자동화 도구 및 역량들이 회사마다, 프로젝트마다 다르기 때문에, 우리는 이 보고서에서 트렌드에 대한 몇가지 관찰을 수행하려고 합니다.
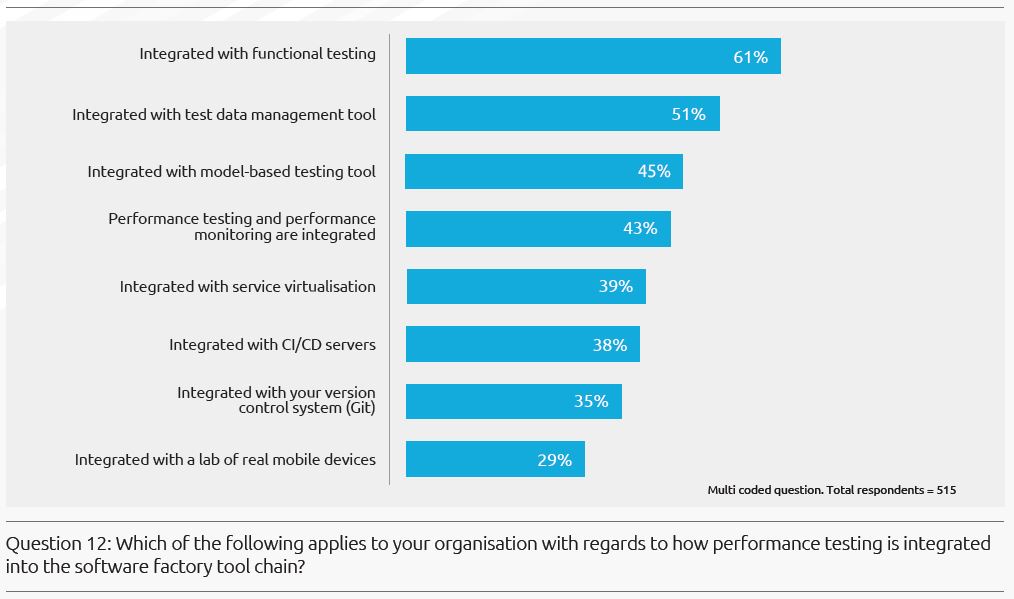
대부분의 조직에서는 수행하기 쉽고 종속성이 더 적다는 이유로, Performance Testing 보다는 Functional Testing의 자동화에 우선순위를 두는 경향이 있습니다. 자동화된 기능테스트는 성능을 측정하는 관점에서 몇가지 시너지를 제공할 수 있습니다.
- 예를 들어, 자동화된 기능테스트는 Software Build Pipeline의 일부로서, 초경량 단일 사용자 성능 테스트(an extremely lightweight single user performance test)를 제공하기 위해, 시간(Timing)과 성능지표(Performance Metrics)를 기록하는 활동으로 확장될 수 있습니다.
- 또한, Backend Response Times으로는 최종사용자의 관점에서의 가시성을 제공하기에 불충분했던 전통적인 성능테스트를 보완하기 위해, 프로토콜과 APIs를 통해 Web Front Ends의 성능 테스트를 수행할 수 있습니다.
“61% integrate functional and performance testing”
지난 인터뷰에서, 한 대형 보험사는 전통적인 부하 테스트로 시작했지만, 곧 응답시간 측정에 대한 내부적인 시야를 확보하기 위해, 자동화된 기능 테스트와 결합을 수행했다고 언급했습니다. 어떤 모바일 테스팅 자동화 도구는 부하 테스트 계획으로 곧바로 포함될 수 있는, 기능적인 스크립트를 생성할 수 있습니다. 팀은 하나의 동기화된 세션에서, 성능 및 기능테스트를 위한 하나의 단일 스크립트를 생성하고, 기록하고, 실행시킬 수 있습니다.
이러한 트렌드는, 특히 성능 관점의 User Stories를 테스트하기 위해, 기존의 기능 테스트 스크립트를 활용하고자 하는 Agile Teams과 관련이 있습니다. 이 아이디어는 실제로 프로세스를 단순화하고 가속화합니다. 하지만, 이러한 목적을 위해 필수적으로 설계되지 않은 성능 시나리오들에 대해서는, 여전히 재작성에 대한 추가적인 투자가 요구됩니다.
“45% integrate model-based testing”
정확하고 대표성을 가진 테스트 계획을 구축하기 위해서는 설계 요구사항이 중요합니다. 그러나, 많은 프로젝트들이 이 부분이 결핍된 상태로 단조로운 테스트가 수행되고 있으며, 부하(Load)를 Positive, Negative, 그리고 Edge Cases와 결합하는 시나리오는 거의 포함되지 않고 있습니다. 이러한 약한 테스트는 자신감을 가지고 Sprint 내에서 변화에 대응하고자 하는 능력을 제한합니다.
MBT(Model-based testing)는 시스템을 대표하는 모델을 사용함으로써 자동화된 테스트를 생성합니다. 이러한 작업은 생성, 작성, 그리고 요구사항 변경에 대응하는 모델의 업데이트를 포함합니다. 모델은 초기 단계에서부터 최종 사용자의 필요와 기대를 인지하고 수용하기 위해 설계될 수 있습니다. MBT는 기능 테스트의 정확성을 높이기 위해 이미 인기를 얻고 있습니다. 그러나, 성능테스트에서도 마찬가지로 사용자 흐름과 트래픽 패턴을 우아하게(elegantly) 모델링할 수 있는 잠재력을 가지고 있습니다. MBT를 사용하는 것은, 비즈니스 분석가부터 개발자와 테스터에 이르기까지, 이해관계자들이 동일 Cycle과 Sprint에서 잘 정렬되어 머물면서도 유연성을 가질 수 있도록 맞추어 줌으로써 강력한 테스트를 가능하게 합니다.
“43% integrate performance testing and monitoring”
43%의 기업들만이 ‘Application Performance Monitoring’을 상용전 데이터(Pre-production Data)와 통합하였습니다.
상용환경 내 App 사용에 대한 가시성을 제공함으로써, Performance Monitoring은 Performance Tester’s Toolkit에서 기본적인 자동화 도구가 되어가고 있습니다. 그 목표는 선제적인 Cross-team Approach를 통해, 상용 전 활동들의 연관성을 개선하기 위한 것입니다. Unified Performance Platform은 모니터링을 통해 데이터를 결합하고, 각 Build의 품질을 테스트하고 평가합니다.
우리는 테스트를 매우 정확하게 수행하기 원합니다. 모니터링 자동화 도구는 성능 테스트 수행 시 추가적이며 깊은 통찰력을 제공합니다. 실제의 트래픽은 상용환경에서 구동되는 Synthetic Probes를 설계할 수 있습니다. 이러한 Synthetic Probes의 결과는 상용 시스템에 대한 빠르고 정확한 피드백을 제공합니다. 예를들어, 부하 변동(Load Variations), 성능저하(Degradations), 그리고 최종 사용자의 경험(End Users’ Experiences)을 측정합니다. 요구사항이 명확하지 않을 때, 성능테스트와 모니터링이 통합된 Proves를 몇몇 이해관계자들에게 공유하는 것은 유용합니다. 이를 통해, 위험을 식별하고 문서화하고 예측할 수 있게 됩니다.
Towards a culture of metrics
우리는 시스템을 탄력적으로 만들어가는 과정을 측정할 필요가 있습니다. 우리는 지속적으로 개선하는 문화를 이끌어가기 위해, 투명성과 가시성을 증가시키기 위해, 그리고 의사결정을 가능하게 하기위해 텔레메트리(telemetry)에 의존하고 있습니다. Quality Gates의 일부로서 계산되는 지표(Metrics)들은, 시스템의 개선 또는 저하를 체크하는데 매우 유용하다는 것이 증명되고 있습니다.
전제되는 조건으로서, Application Performance의 정보는 지루한 승인절차나, 보고, 허가를 통할 필요 없이 자유롭게 이용할 수 있어야 합니다. 높은 수준의 투명성을 달성하기 위해서는, 다양한 형태의 저항을 완화시키기 위해 조직적인 변화가 요구될지도 모릅니다. 측정은 최소한 Application Performance를 이해하고, 예측하고, 문제를 해결하는데 도움을 주기위해 필요하다고 믿고 있습니다. 또한, 측정은 성능 저하가 발생하자마자 이슈를 개선하기 위해 시스템을 변경하는것을 가능하게 함으로써, 문제가 예방되는 것을 도울 수 있습니다. 관측 가능성의 개념(The concept of observability)은, 행동과 성능의 관점에서 측정되는 시스템이 얼마나 많이 평가되고 개선될 수 있는지에 초점을 맞춤으로서, 지표(Metrics)를 보완합니다.
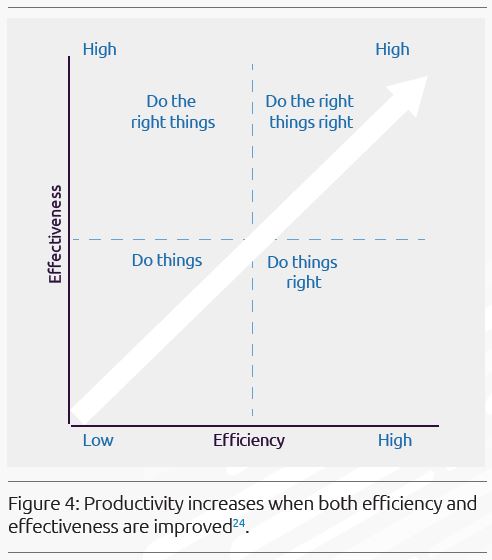
유용한 Performance Indicators를 어떤 것으로 구성할지에 대해 고려하는 것은 가치가 있습니다. 우리의 견해로는, ‘Quality for DevOps teams’가 ‘좋은’ 지표들을 식별하는 것을 돕는데 가치있는 접근을 제공하고 있다고 봅니다. 특히, 이들은 우리의 활동에 대해 효과성과 효율성의 양 측면에서 균형잡힌 지표들을 어떻게 도출해야 하는지에 대해 초점을 맞출 수 있도록 해줍니다.
우리는 유용성에 기반하여, CPIs(Critical Performance Indicators)와 같은 지표를 선택하고 KPIs로 가져갈 수 도 있습니다. 다음 정의는 ISO25010 표준에서의 품질 특성 적용에 대한 우리의 해석에 기반한 내용입니다.
- 효과성(Effectiveness)은 사용자가 명시된 목표를 달성하기 위해 요구되는 정확성(Accuracy)과 완전성(Completeness)입니다.
- 효율성(Efficiency)은 사용자가 정확하고(Accuracy), 완전하게(Completeness) 목표를 달성하기 위해 소비되는 자원(the Resources)입니다. 예를 들어, 유용한 ‘운영 KPIs’는 속도를 개선하는 것을 포함합니다. ‘품질 CPI’(Critical Performance Indicator)는 상용화 이후 발견되는 결함비율(Defect Slippage Rate to Production)일 수 있습니다. ‘비용 KPI’는 자동화의 결과로 절감되는 공수 비율을 포함할 수 있습니다. ‘Speed-to-market KPI’는 Sprint의 속도일 수 있습니다.
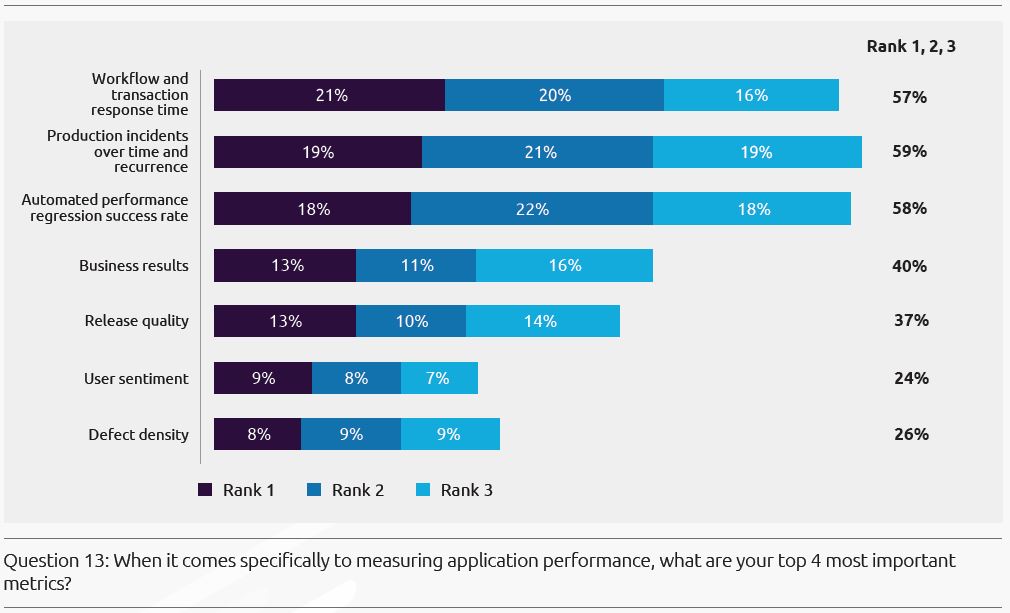
이 설문조사에서의 지표들은 High-level Trends를 반영하기 위해 선정된 것이며, 전체를 다루지는 않습니다. ‘Response Time’(57%)과 ‘Production Incidents’(59%)가 항상 높은 점수를 받을 동안에, 우리는 비즈니스 성과, 배포 품질 및 사용자 정서를 고려하는 업무의 효과들을 측정에 포함하기 위해, 우리의 사고를 확장할 필요가 있습니다. 이러한 행동은 상당히 자기 성찰적(Introspective)이고, 큰 맥락으로부터 분리되어 있는 것처럼 보일 수도 있습니다. 정렬의 결핍은 개선의 문화보다는, 중단과 충돌에 대한 비난의 문화를 퍼뜨리게 될지도 모릅니다.(The lack of alignment may propagate a culture of blame around outages and crashes rather than a culture of improvement.)
너무 많은 자동화 도구들이 동시에 실행될 때, 성능의 단일 관점에서 지표를 얻기 어려울 수 있지만, 조직들은 제공되는 가치에 대해 공동의 합의(collective understanding)를 가질 필요가 있습니다. 어떤 지표 목록이든 제공되는 가치와 그것이 주는 영감을 따라 진화해야 합니다.
Online Transactions의 경우, 다음의 상업적인 지표들이 고려될 수 있습니다.
- 전반적인 비즈니스 성과: conversion rate, traffic, page views, session duration, bounce rate
- 고객: repeat rate, customer lifetime value, etc.
- 주문: average revenue, number of items
- 수익성: customer acquisition cost (amount spent on performance engineering / number of customers), cost of selling, margin
모든 성능 지표를 구조화할 수 있는 것은 아닙니다. 예를 들어, 사용자 정서는 정량화하기 어렵습니다. Performance Engineering에 대한 사용자 정서(24%)의 유용성을 촉진하기 위한 한 방법으로, 우리는 자연어 처리 알고리즘에 의한 특정 KPIs 설정을 고려해 볼 수 있습니다. 이것은 피드백의 양극성(긍정, 중립, 부정), 가치(실행가능함, 해결됨, 보관됨), 그리고 감정의 유형과 수준(행복, 평온, 실망, 성가심, 좌절, 분노)을 결정하는데 도움을 줍니다. 소셜 미디어 활동을 조사함으로 부정적인 감정이 공유되는 것에 대한 경고를 확인할 수 있습니다. 장기적으로, 댓글은 기존의 전략을 리모델링 하는데 사용될 수 있습니다.
Performance engineering and the cloud
‘Cloud Load and Performance Testing’의 이점은 매우 강력합니다. 외부의 탄력적인 요청에 의해 발생할 수 있는, 애플리케이션의 현실적인 테스트를 하기위해 요구되는 모든 부하를 발생시킬 수 있습니다. 팀들은 이러한 환경을 구축하거나 유지할 필요가 없습니다. 지리적으로 분산된 부하를 가능하게 하는 추가적인 이점은, Performance Engineer가 보다 현실적인 테스트를 실행 가능하도록 합니다.
설문조사에 따르면, Load Testing Infrastructure의 대부분(74%)이 현재 Cloud에서 운영되고 있으며, 이러한 트렌드는 향후 12개월 안에 76%까지 증가할 것으로 예상되고 있습니다.
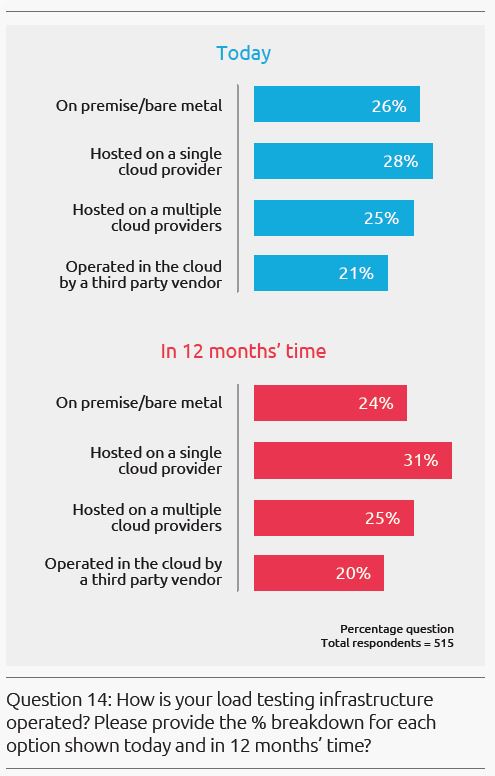
Performance Engineering과 Cloud의 관계는 단순히 Cloud에서 테스트를 하는 것만을 말하는 것은 아닙니다. 여기에는 Cloud based Application을 테스트하는 것이 포함되어 있으며, 그것이 Native Cloud Application이든 On Premise에서 Cloud로 마이그레이션을 한 시스템이든 상관 없습니다.
Cloud Computing은 확장 가능한 On-demand Computing Power를 보다 낮은 비용으로 공급하는 것을 약속하는, 파괴적인 기술 혁신입니다. 하지만, Cloud-based Systems의 복잡성은 Performance Engineering을 더욱 더 필요하게 만듭니다. Applications Architecture에 대해 완전한 이해없이 오로지 탄력적인 서버 확장성에만 의존하는 것은, Performance Bottlenecks을 숨긴채로 비용만 증가하게 만드는 것으로, 애초의 Cloud로의 배포 목적이 좌절되는 결과를 초래하게 만듭니다.
Performance Engineers는 Cloud Systems이 당면한 도전 과제들을 잘 알고 있습니다
- Delivery Chain 전반에 걸친 Troubleshooting은 매우 복잡합니다. Advanced APM Solutions을 통해 부하테스트가 진행되는 동안 Cloud-based System을 모니터링 함으로써, 문제가 어디에 존재하는지에 대한 깊은 가시성을 제공할 수 있습니다.
- Reproduce-ability 테스트를 수행하는 것은 어렵습니다. 부하 테스트가 실행중일 때, 자원들이 실제로 어떻게 할당되어 있고, 경합(Contention) 중인지는 알기 어렵습니다.
- Serverless는 최적의 성능을 의미하지는 않습니다. Serverless Functions는 Cloud 환경에서 더 많이 퍼져있습니다. 하지만, 성능이 떨어지는 Code는 실행되는 애플리케이션, 가상머신, 또는 Serverless Functions에 상관없이 문제를 일으킵니다. 애플리케이션의 인프라와 행동을 이해하는 것은, 성능 병목현상을 식별하는데 핵심적입니다.
클라우드로 마이그레이션하는 것은 많은 이점을 가지고 있습니다. 기업은 인프라 비용을 최적화할 수 있고, 사용자에게 제공하는 서비스의 규모와 품질을 높일 수 있습니다. 포괄적인 수준으로 보증하는 State-of-the-art Performance Testing은 마이그레이션 프로세스의 일부입니다.
[다음 글에서 Chapter 5가 계속됩니다.]
Source: https://www.us.sogeti.com/explore/research/reports/state-of-performance-engineering/