
Direct path read 와 block cleanout 그리고 latch: row cache objects
Updated:
Adaptive direct path read 기능의 의외의 위험성
11g에서 등장한 adaptive direct path read..
serial full table scan 에서도 적극적으로 direct path read 를 사용하는 이 기능.. 장점이 많으니까 채용되었을 것이다. 하지만 특수한 상황 속으로 들어가면 오히려 단점이 될 수도 있다.
아래의 간단한 테스트를 먼저 보면, delayed block cleanout 을 유발시키기 위해 update 후에 바로 buffer cache 를 flush out 시킨 후 commit 시켰다.
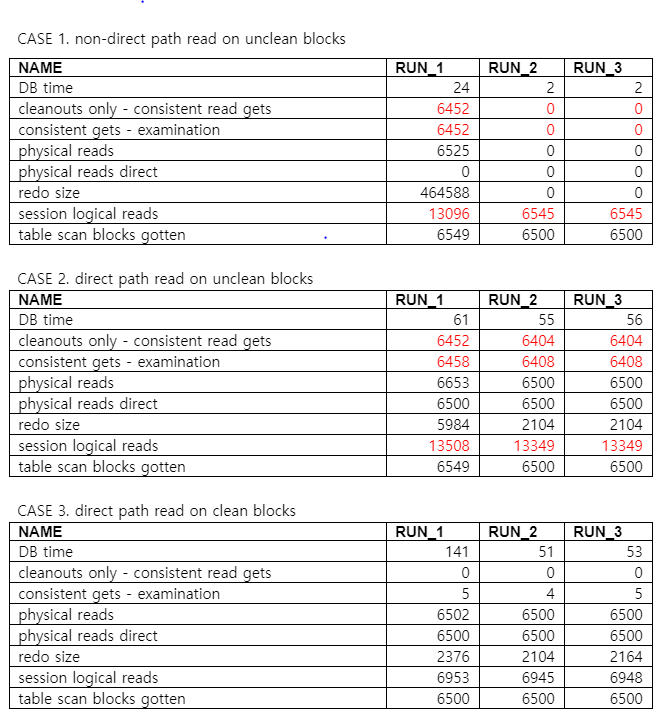
이제 CASE 각각의 경우의 결과를 비교해 보면,
우선 CASE 1. non-direct path read on unclean blocks 의 경우 Run 1. 에서 block cleanout 이 완료되었으므로 Run 2,3 에서는 cleanout 이 수행될 필요가 없다. 반면, CASE 2. direct path read on unclean blocks 경우엔 매 수행 때마다 block cleanout 이 필요한 상태로 남아있는 것을 볼 수 있다. direct path read 방식으로 블럭이 액세스 될 때는 block cleanout 을 수행하지 않기 때문이다. 이 때문에 cleanout 되지 않은 블럭을 읽을 때마다 consistent gets - examination 이 발생되며 이 수치는 session logical reads 에 더해지게 된다. 즉, logical read 가 늘어나는 것이고 DB 는 무거워지는 것이다.
Cleanout 되지 않은 블럭이 많은 테이블이라면 direct path read 는 비용이 크다고 할 수 있는 것이다. 특히 반복해서 access 한다면 더욱 더!
[session A]
update dir_test set c2 = ‘BBBBBBBBB’
where rownum <= 1000000;
alter system flush buffer_cache;
commit;
[session B]
이제 좀 더 나아가 얘기하고 싶은 게 있다. 그것은 latch: row cache objects 이벤트와 관련되는 이야기이다.
당시 내가 만난 그 시스템은 매우 큰 규모였다. RAC node 수만 6개에 CPU core 수는 700 이 넘었다. 그래서인지 online 되어있는 undo segment 의 수가 10,000개가 넘었다.
배치용으로 쓰는 인스턴스에서는 고질적으로 latch: row cache object 이벤트가 계속 발생했고, 한번은 이 현상이 심해지면서 인스턴스가 hang 상태가 되어 긴급하게 restartup 한 적도 있었다.
나중에야 비로소 그 원인을 알 수 있게 되었는데, 바로 direct path read 와 관련이 있었던 것이다.
위에서 이야기했듯이 direct path read 는 block cleanout 을 수행하지 않는다. consistent gets - examination 이 매번 발생되는 이유는 단지 read consistency 를 위해 undo header 를 lookup 하기 때문일 것이다. direct path read 가 cleanout 을 하지 않기 때문에 그만큼 DB 내에는 cleanout 되지 않은 block 들이 점점 늘어나게 되었고, 이는 다시 consistent gets - examination, 즉 undo TX table lookup 이 계속 증가하는 원인이 되었다.
또한, 앞에서 잠깐 언급했듯이 시스템 용량이 커서 그런지 인스턴스 기동시 자동으로 online 시키는 undo segment 가 10,000개가 넘었는데, 이것은 direct path read 에 의한 빈번한 undo TX table lookup 과 함께 Row Cache 안에서 Latch 경합을 크게 가중시키는 원인이 되었다.
Row Cache 는 10,000개가 넘는 undo segment 정보를 매우 빈번하게 load 하고 search 할 수 있어야 했던 것이다.(일반적으로 제법 큰 DB 라고 해도 undo segment 의 갯수는 1000 개 내외임.)
원인을 알고나니 해결책은 오히려 단순했다. 문제의 근본원인은 cleanout 되지 않은 블럭들이 늘어나는 것이었으므로 이 부분에 대한 해결책을 고안했다. 어쩌면 다른 더 좋은 방법이 있을지도 모르겠지만 이 방법도 나쁘진 않았다. 변경이 많이 발생되는 테이블을 주기적으로 수동 cleanout 시키는 방법이었다.
non-direct path read 방식으로 이런 테이블들과 인덱스들을 주기적으로 full scan 해 주는 간단한 프로시저를 만들어서 JOB 에 등록시켰다. 효과는 좋아서 이후 latch: row cache objects 는 말끔히 사라졌다!
11g 에서 등장한 adaptive direct path read 는 분명 좋은 기능이다. 하지만 상황에 따라 그 비용은 비쌀 수 있다. 특히 배치업무에서 발생시키는 많은 수의 unclean block 들이 늘어나는 것에 대한 대비책이 있어야 한다. parallel query 를 주로 사용하는 배치환경이라면 cleanout 되지 못한 블럭들이 아마도 점점 늘어나고 있을 것이다. 적절한 테이블 reorg 및 인덱스 rebuild 와 함께 주기적인 수동 block cleanout 은 좋은 해결책이 될 수 있을 것이다. 만일 online 되어있는 undo segment 수가 너무 많으면 그 수를 적절하게 줄여주는 것도 필요할 것이다.