
VIP 절체와 CTF(connect time failover) 그리고 connection pool 의 특성과 장애사례
Updated:
장애 상황과 증상
2-node RAC 였다.
평소 서비스(SVC) AP는 db#1 을 바라보고 붙어 있었다. (아래 tnsnames.ora 참조)
00시 00분 PM 작업을 위해 db#1 인스턴스를 shutdown immediate 로 내렸다. 그리고… 장애가 시작되었다.
화면이 뜨질 않았다. 몇몇 사용자는 화면은 떴으나 성능이 너무 느렸다.
AP(WAS) 를 재기동했지만 상황이 나아지지 않았다.
… 많은 일들이 지나가고…
00시 47분 db#1 인스턴스를 startup 시켰다.
그러자 갑자기 화면이 팡팡 뜨면서 장애가 해결되었다!!
tnsnames.ora 설정
SVC1 =
(DESCRIPTION =
(FAILOVER=on)
(ADDRESS_LIST =
(LOAD_BALANCE=on)
(FAILOVER=on)
(ADDRESS = (PROTOCOL = TCP)(HOST = svc_db1_vip)(PORT = 1522))
(ADDRESS = (PROTOCOL = TCP)(HOST = svc_db1_vip)(PORT = 1523))
(ADDRESS = (PROTOCOL = TCP)(HOST = svc_db1_vip)(PORT = 1524))
)
(ADDRESS_LIST =
(LOAD_BALANCE=on)
(FAILOVER=on)
(ADDRESS = (PROTOCOL = TCP)(HOST = svc_db2_vip)(PORT = 1522))
(ADDRESS = (PROTOCOL = TCP)(HOST = svc_db2_vip)(PORT = 1523))
(ADDRESS = (PROTOCOL = TCP)(HOST = svc_db2_vip)(PORT = 1524))
)
(CONNECT_DATA = (SERVICE_NAME = SVC))
)
장애 원인분석
db#2 listener.log 를 엑셀에 담아서 차트를 그려 보았다. AP 가 db#2 로 connection fail-over 한 흔적을 보기 위해서다.
아래 차트를 보면 일정한 간격으로 connection 이 한개씩 만들어지다가 db#1 인스턴스가 올라온 00시 47분에 connection 이 갑자기 많이 만들어진 것을 볼 수 있다.
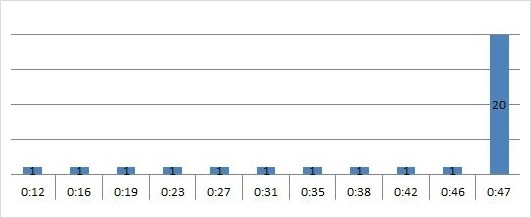
로그파일에서 접속시간을 초단위까지 보면 정확히 3분49초 간격으로 connection 이 만들어진 것을 볼 수 있었다.
또한, 00시 47분에 db#1 인스턴스에서는 ORA-12514 (TNS:listener does not currently know of service requested in connect descriptor) 에러와 ORA-12528 (TNS: listener: all appropriate instances are blocking new connections) 에러가 많이 떨어져 있는 것도 확인할 수 있었다.
원인은 이렇게 정리되었다.
-
db#1 인스턴스를 shutdown immediate 로 내렸으므로 virtual IP 는 db#2 인스턴스로 넘어가지 않았다 - VIP 는 인스턴스가 비정상적으로 종료될 경우에만 CRS 가 다른 인스턴스로 넘겨주기 때문임. vip1 어드레스 3개는 그냥 사라져 버린 것이다.
-
VIP 가 db#2 로 넘어가지 않았으므로 AP 의 tnsnames.ora 설정상 CTF(connect time fail-over) 가 발생되었으며, 이때 vip1 어드레스 3개를 찾는데 소모된 TCP timeout 시간합이 3분 49초가 되었다. vip1 어드레스 3개를 모두 찾아본 후에(즉, 3분 49초 후에) vip2 어드레스중 1개를 찾아서 connection 을 만든 것이다.
WAS 가 connection 을 만들 때 순차적으로 만들기 때문에 connection 을 1개씩 만들어 갔다. -
이렇게 3분 49초 에 한개씩 connection 총 10개를 만들어 가다가 00시 47분에 20개의 connection 을 순식간에 만들었는데, WAS connection pool initial 설정 갯수가 30개 였기 때문이다.
-
00시 47분에 나머지 20개의 connection 을 순식간에 만든 이유는 이때 db#1 인스턴스가 기동되었기 때문이다.
즉, db#1 인스턴스가 기동되는 순간부터 AP는 vip1 을 detect 할 수 있기 때문에 TCP timeout 은 발생하지 않는다. 하지만 아직 db#1 리스너에 인스턴스 정보가 등록되는데는 1분 정도의 시간이 필요하므로 db#1 리스너에는 ORA-12514, ORA-12528 에러를 남기고 db#2 리스너로 connect time fail-over 가 순식간에 20개가 발생된 것이다. -
WAS 가 connection 을 3분49초마다 1개씩 천천히 만들긴 하더라도 그때 그때 만들어진 connection 을 이용하여 서비스를 할 수 있을 것으로 생각할 수 있다.
그러나, 테스트 결과 그렇지 못했다. WAS 는 connection pool (설정값 30개) 을 완성하지 못한 상태에서는 정상 서비스하지 못했다. db#1 인스턴스가 기동되면서 순식간에 connection pool 이 모두 완성된 다음에야 비로소 장애가 풀렸던 것도 이 때문이다.
재발방지 대책
shutdown immediate 로 인스턴스를 내리는 것은 의도된 인스턴스 Shutdown 이므로(장애가 아닌 것으로 해석됨) 이 경우 VIP 가 fail-over 되지 않는다.
따라서, VIP 가 fail-over 되도록 DB서버 자체를 재기동하거나, 수동으로 vip 를 넘긴 다음에 인스턴스를 shutdown 하면 되겠다.