
MVIEW Refresh 가 성능에 영향을 미친 사례
Updated:
MVIEW Refresh 가 성능에 영향을 미친 사례
제니퍼에서 SQL 응답시간이 주기적으로 튀는 모습이다. 튀는 SQL 들은 주로 특정 MVIEW 를 액세스하는 쿼리들이었다. 평소에는 빠른 쿼리들이 주기적으로 튀는 현상이었다.
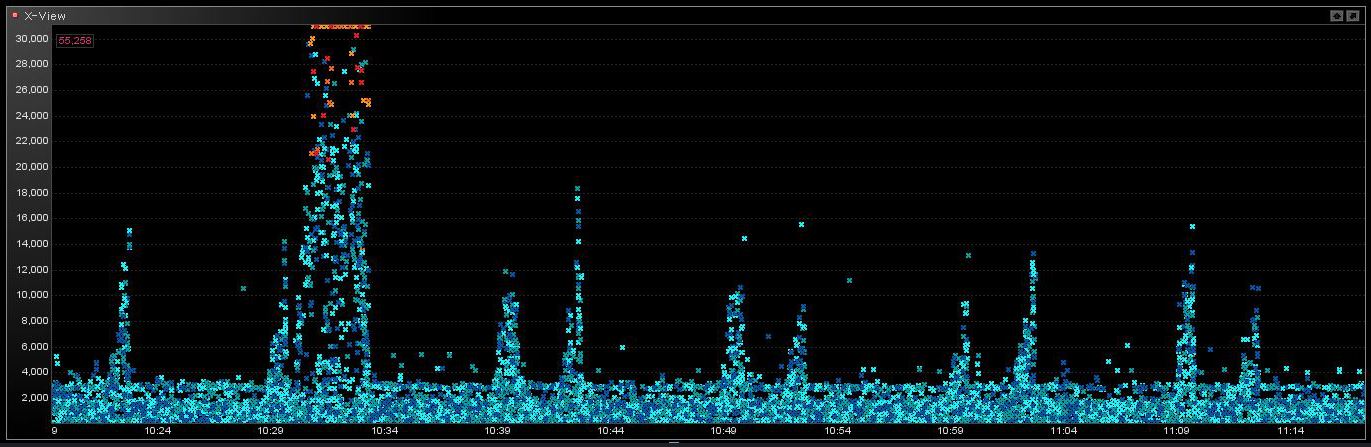
아래는 튀는 현상이 발생될 때 디콘(Deacon) 인스턴스 모니터의 모습이다. Undo record(Undo_rec) 가 발생되고 Redo Log(Rdo(m)) 가 초당 10 ~ 22 mb 가 발생되고, crd% ( ‘session logical reads’ 에 대한 ‘data blocks consistent reads - undo records applied’ 의 비율) 가 50% 나 발생되고 있었다. 또한 이 현상은 RAC 를 구성하는 두 노드에서 랜덤하게 발생되고 있었다.
이것은 어떤 세그먼트(여기서는 MVIEW 였음)에 50초 정도 동안 변경이 발생되고 있고 이 영향으로 읽기일관성(read consistency) 부하가 증가된 상황임을 말해준다.
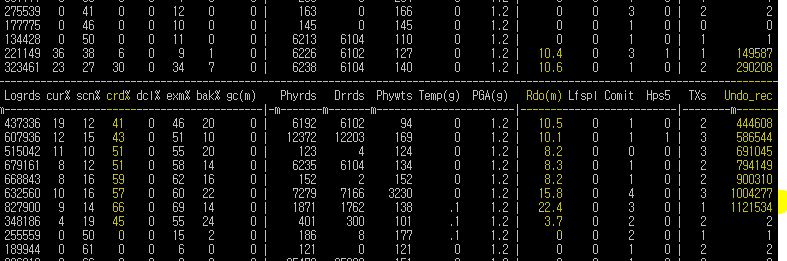
아래의 두 차트를 보면 SQL 응답시간이 튀는 상황의 DB Wait 시간이 증가되었는데 Wait 원인은 RAC 노드간 전송속도가 느려졌기 때문인 것을 알 수 있다.
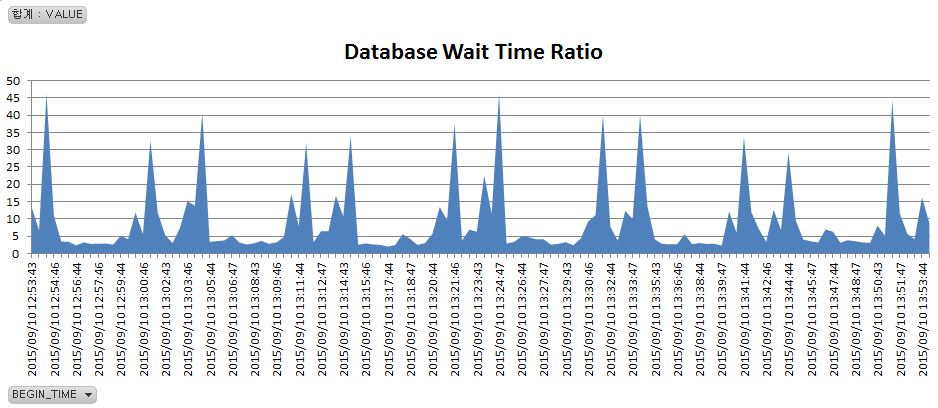
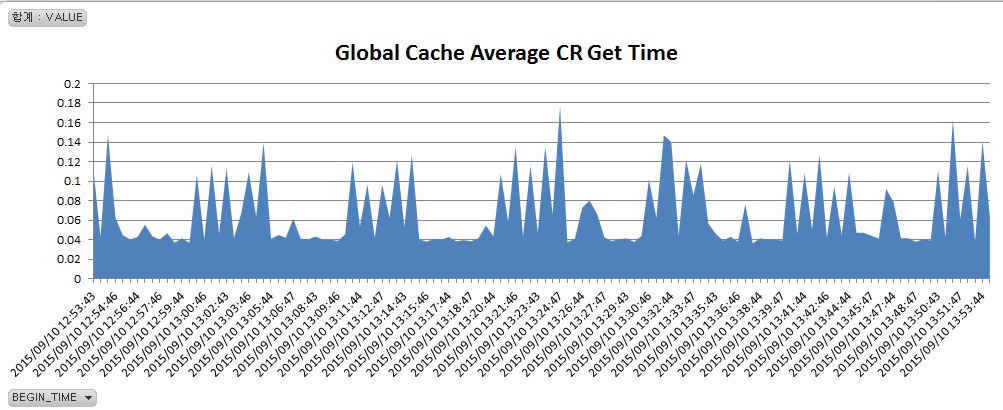
그렇다면 왜 RAC 노드간 블록 전송속도가 느려진 것일까. 아래의 두 차트를 보자. MVIEW 가 약 50초 동안 변경중이므로(변경시작부터 commit 까지 50초) 이 시간 동안 이 MVIEW 를 액세스하는 다른 세션들의 쿼리들은 읽기일관성 읽기를 해야 한다. 그런데 읽기일관성 읽기에 필요한 Undo 가 Local Node 에 있지 않고 Remote Node 에 있다면 Remote Node 로부터 GC CR(Consistent Read) 블록을 받아와야 한다. 즉 Remote Node 의 LMS 에게 필요한 Undo record 들을 가지고 CR 블록을 만들어서 전송해 달라고 부탁해야 한다.
이것은 위쪽의 Deacon 인스턴스모니터 캡처화면에서 bak% 가 높은 것을 보면 알 수 있다. bak% 는 ‘session logical reads’(Logrds) 중에서 background process 들의 portion 을 의미한다. LMS 가 다른 노드로부터 부탁을 받아 상대 노드에게 필요한 CR 블록을 많이 만들어 내고 있는 상황임을 말해 준다.
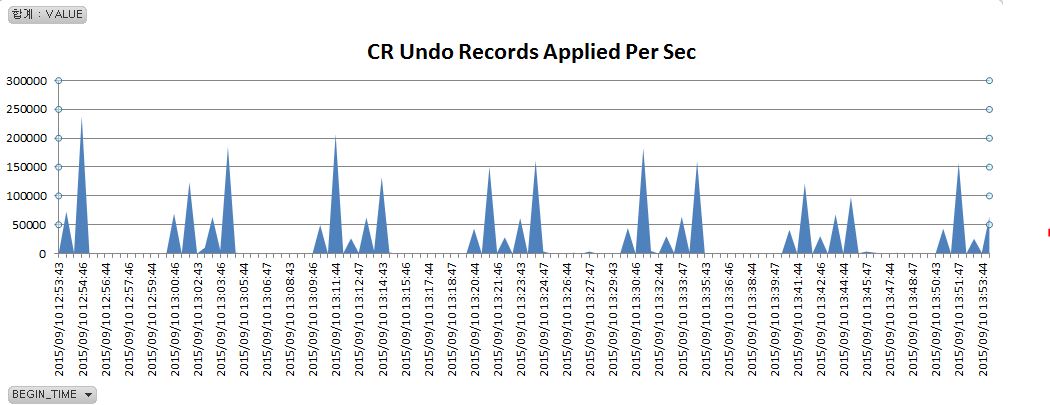
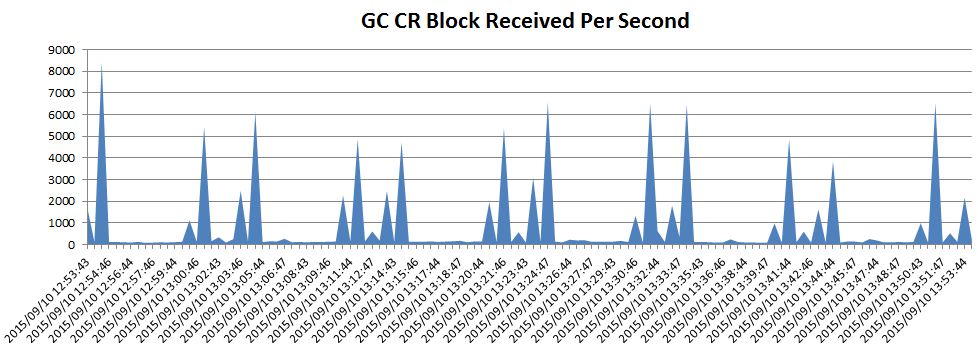
그런데 왜 RAC 노드간 블록 전송속도는 느려진 것일까. 이것은 아래 차트를 보면 힌트를 얻을 수 있다. MVIEW 가 Refresh 될 때마다 많은 Redo Log 가 발생되었다.(이 MVIEW 는 Complete Refresh 방식이었는데 이 방식은 전체 Row 를 모두 delete 한 후 새로 conventional 방식으로 insert 하게 되는데, delete 나 conventional insert 모두 Redo Log 를 많이 발생시킨다. MVIEW 가 Refresh 되는 동안 읽기일관성을 제공하기 위해서는 이렇게 작업할 수 밖에 없는 것이기도 하다.)
Redo Log 가 많이 발생된다는 것은 LGWR(Log writer) 에 부하가 간다는 뜻이다. 그런데 LMS 가 CR 블럭을 만들어서 다른 노드로 전송하기 위해서는 관련하여 생성된 Redo Log 를 Redo Log 파일로 Flush out 시킨 후 전송해야 한다. 안그래도 바쁜 LGWR 인데 이 작업까지 하려니 Waiting 이 걸리는 것이다.
일반적으로 Redo Log 가 순간적으로 많이 발생되는 작업이 있을 때 Cluster wait 들이 많이 발생되는 이유가 이 때문이다. LGWR 가 바쁘기 때문이다. 아래 차트를 보면 Remote 노드에서 Redo Log 가 많이 발생될 때 Local 노드에서 GC CR 블럭 get time 이 증가한 것을 볼 수 있다.
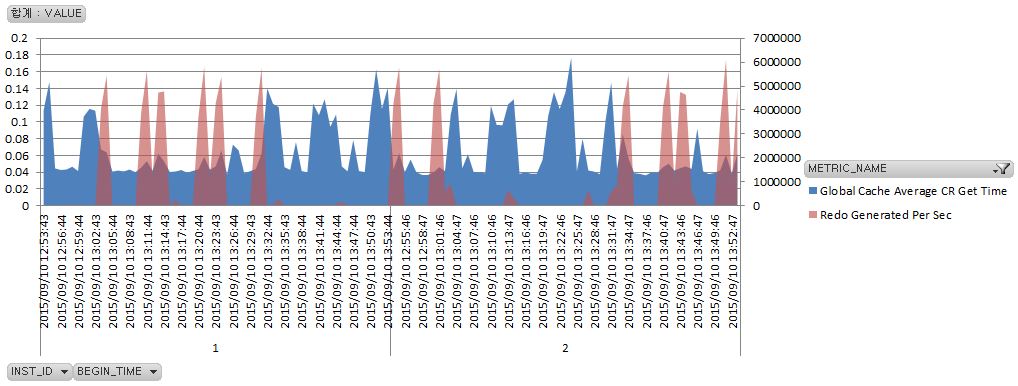
정리해 보면, 평소에 빠르던 특정 MVIEW 를 액세스하는 쿼리가 MVIEW 를 Refresh 할 때마다 느려진 이유는 아래와 같다.
- 읽기일관성 읽기 부하가 얹혀져서 Logical read 가 증가했다.
- MVIEW Refresh 가 Remote Node 에서 발생된 경우 읽기일관성 Logical read 에 필요한 CR 블록들을 Remote Node 의 LMS 로부터 받아오는 과정이 추가되었다.
- 이 과정 또한 Remote Node 의 LGWR 가 MVIEW Refresh 때문에 많은 Redo Log 를 디스크의 Redo Log 파일로 write 해야 하는 I/O 가 busy 한 상황에서 이루어 져야 했다.
Note.
이 사이트의 경우 해결책으로 MVIEW Refresh 주기를 늘리는 것을 선택했다. 현재 10분간격 Refresh JOB 이 2개 돌고 있는 것을 불필요한 JOB 한 개를 drop 시키고 Refresh 주기도 1시간 이상으로 늘리기로 한 것. 사실 근본적인 해결책은 MVIEW Refresh 와 MVIEW 를 액세스하는 쿼리들을 한 노드로 고정시키는 것이었다. 즉 노드별 Application Partitioning 이 정답이라고 할 수 있겠지만 아쉽게도 이 사이트에는 적용할 수 없었다.
읽기일관성 읽기부하의 증가 때문에 서비스 장애 또는 품질저하가 발생되는 경우 두 가지가 문제해결의 핵심 포인트이다.
첫째, 원인을 제공하는 트랜잭션(여기서는 MVIEW Refresh)의 길이를 가능한 짧게 가져가야 하는 것과 둘째, 노드별 Application Partitioning 이다.
전자는 읽기일관성 읽기부하 자체를 최소화시키고 후자는 RAC Cluster waiting 을 방지해 준다. 여기에 한가지를 더하자면 원인제공 트랜잭션에서 발생시키는 Redo Log 양을 최대한 줄여서 LGWR 의 부하를 줄여주는 것이다.