
LMS(Global cache service) 가 튄다?
Updated:
LMS(Global cache service) 부하가 증가하며 장애가 발생되는 사례
OO은행 차세대 프로젝트에서 경험한 일이다.
오픈여부를 결정하는 최종 전점테스트, 환경은 3-node RAC Oracle 11g.
테스트 시작후 1시간여가 지나자 평소 100 블럭액세스로 빈번히 수행되던 가벼운 쿼리A가 갑자기 수십만 블럭을 액세스하는 무거운 쿼리로 등장했다. 실행계획은 변경되지 않았다!
그런데 특이한 것은, 이 때 한 인스턴스의 LMS(Global cache service background process) 의 블럭 액세스(logical reads) 부하가 갑자기 초당 수십만 블럭으로 증가했다는 것이다. 이 때문에 LMS 는 과부하 상태가 되었고 gc(global cache) wait 들이 대량으로 발생하며 전체 시스템은 hang 상태로 빠지고 있었다.
LMS 는 RAC 노드들 사이에서 데이터 블럭들을 전송해 주는 역할을 한다. 이 백그라운드 프로세스의 일반적인 logical read 부하는 초당 100 블럭을 넘지 않는다. 초당 수십만 블럭을 액세스 하면 무언가 잘못된 것이고 시스템은 버티기 어려워 진다.
긴장상황에서 모니터링과 분석이 이루어졌는데, 조사결과 원인은 trouble maker 세션이 있었기 때문이었다. 어떤 배치 데몬세션이 수행되고 있었는데 쿼리A 가 액세스하는 같은 테이블에 주기적으로 데이터를 INSERT 하면서 commit 도 하지 않고 있었던 것이다.
trouble maker 세션을 강제 종료시킨 후 rollback 이 완료될 때까지 한 시간을 기다렸다. rollback 이 완료되자 해당 쿼리A 는 가벼워졌고 LMS 도 가벼워졌고 DBMS 는 정상이 되었다.
아래에 이 현상을 재현하는 테스트를 수행해 보았다.
테스트 환경 구성
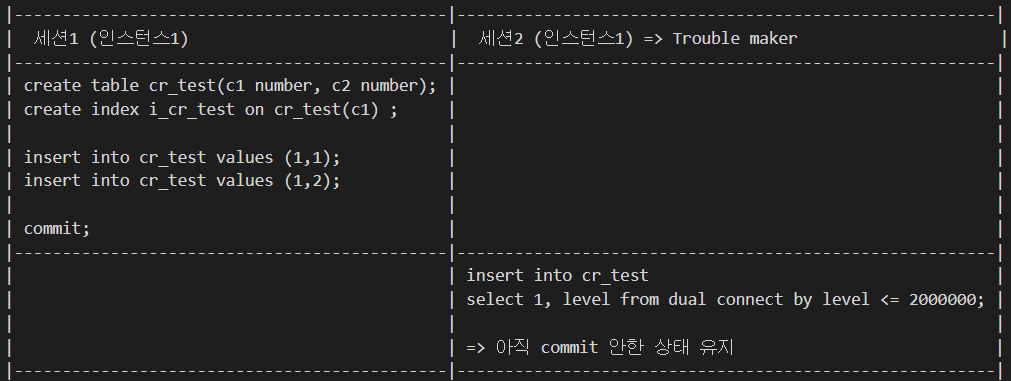
세션1 (인스턴스1)
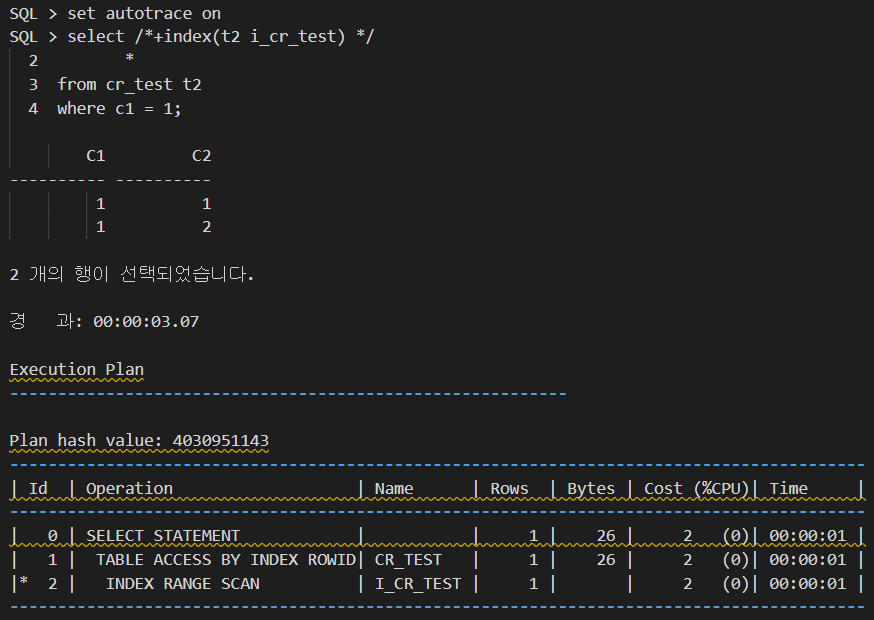
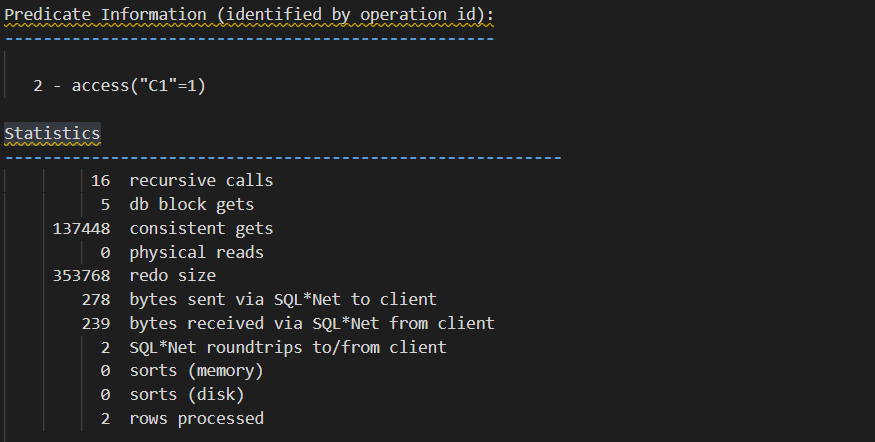
세션2 가 만들어낸 많은 블럭들을 읽어야 하므로 logical read(consistent gets) 가 증가된 모습
세션3 (인스턴스2)
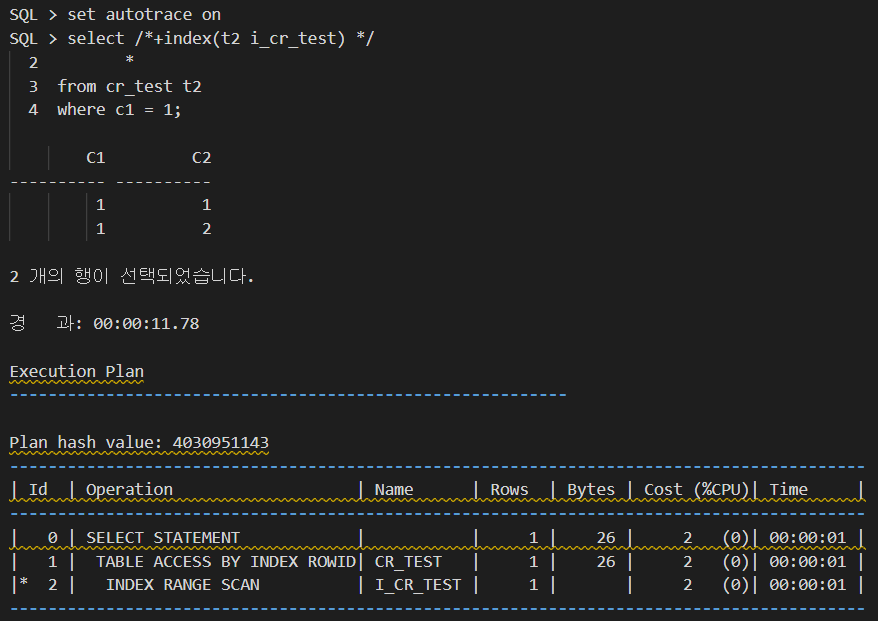
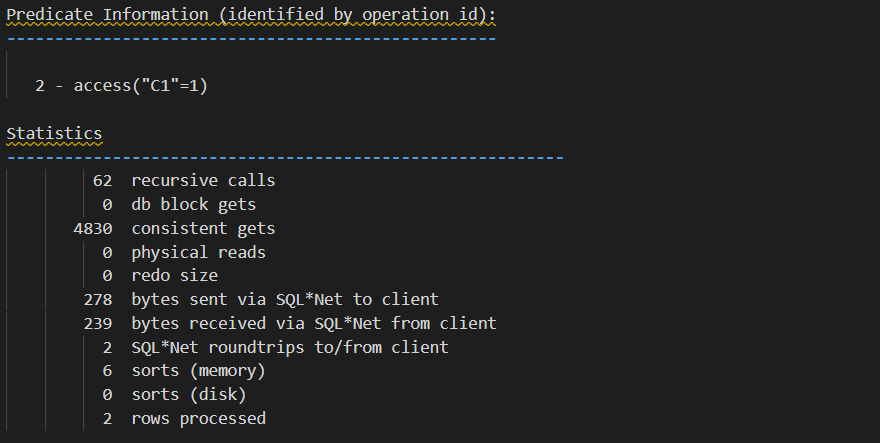
세션1보다 logical read 가 작은데 그 이유는, 1번 인스턴스에 있는 세션1은 쿼리수행 서버프로세스가 직접 uncommitted 블럭(세션2가 만들어낸)들을 읽어 들이는데 반해, 다른 인스턴스에 있는 세션3은 1번 인스턴스의 LMS 를 통해서 이 일을 수행하기 때문에 트레이스에는 잡히지 않은 것임.
왜냐 하면 쿼리가 액세스 해야 하는 undo segment 는 1번 인스턴스에 할당된 undo tablespace 에 있기 때문에 다른 인스턴스에서 이 쿼리가 수행되면 1번 인스턴스의 LMS 가 데이터 블럭과 undo segment 를 읽어서 그 결과를 요청한 인스턴스의 쿼리수행 세션에게 보내주기 때문이다.
아래 인스턴스1의 LMS 를 모니터링한 화면을 보면 알 수 있다.
LMS 세션 (인스턴스1) - 디콘세션모니터로 조회
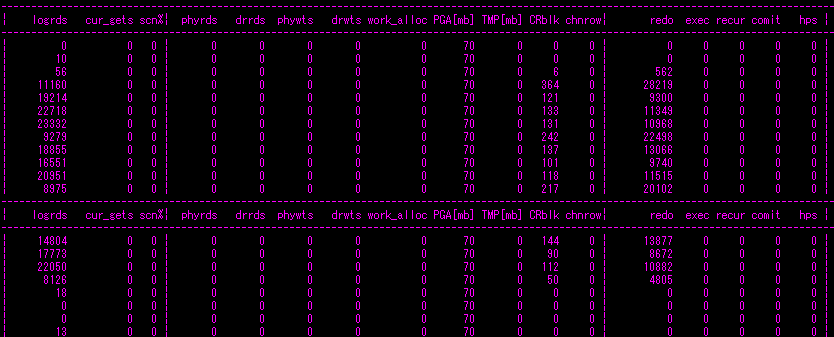
인스턴스2의 세션3이 쿼리를 수행할 때, 인스턴스1 의 LMS 는 인스턴스2 로 세션2 가 만들어낸 블럭들을 전송해야 되므로 logical reads 가 급격히 증가한다.(redo log 도 좀 발생함) 이 상황이 계속되면 LMS 가 과부하 상태이므로 시스템은 gc wait 들이 많이 발생되며 slow performance 상태가 된다. 심하면 인스턴스는 hang 상태에 빠지게 되는 것이다.
마치며
이 사례에서 보듯이 대량의 데이터를 추가/변경하는 트랜잭션은 반드시 commit 으로 종결시켜 주어야 한다. 그러지 않으면 해당 테이블을 액세스하는 타세션들의 쿼리들은 무거워질 수 있으며, RAC 환경이라면 LMS(global cache service) 에 부하가 가중되면서 DBMS 성능에 큰 문제가 생길 수 있다.
또한, 이런 Long 트랜잭션들은 동시사용자가 한산한 야간에 배치로 수행시키는 게 바람직하며, 어쩔수 없이 주간에 수행시켜야 한다면 중간중간 commit 을 넣어 주어 타세션에 대한 성능영향을 최소화해야 한다.