
MariaDB 온라인쇼핑몰 성능이슈 해결과정 1편
Updated:
MariaDB 온라인 쇼핑몰 성능이슈 해결과정 1편
MariaDB를 사용하여 대량의 트랜잭션을 처리하는 온라인 쇼핑몰 사이트였다. 설 연휴 전 2주간은 프로모션에 의한 매출이 집중되는 기간으로, 고객으로부터 성능 모니터링/튜닝 요청을 받아 성능 장애요인 제거 및 개선방안을 제시하였다.
2주간 여러가지 장애상황 발생하였으며, 성능 이슈사항을 해결해 나가는 문제해결 과정에 촛점을 맞추어 작성하려고 한다.
1일차:회의참석 (Galera Cluster 복제 지연으로 장애발생)
몇일전 MariaDB 성능장애발생(DB Hang)으로 DB를 Restart하였으며, 기술지원 업체의 Galera Cluster gcache 사이즈 조정(128MB > 8GB) 권고에 대한 자문을 요청한 회의였다.
대부분의 사이트에서 MariaDB 복제는 Master-Slave 구조로 Master Node에서만 트랜잭션이 발생하고 Slave에는 비동기 방식으로 구성된다. 그에 반해 해당 사이트는 Galera Cluster 3-Node(Active-Active-Active)로 모든 Node에서 트랜잭션이 발생하며 모든 Node에 트랜잭션 변경 데이터가 복제가 완료되어야 되는 실시간 동기화 방식이었다. 모든 Node에 데이터를 저장하기 전에 확인을 해야 하므로 LOCK문제와 Slow-Query 이슈를 피할 수 없을 것이다.
장애상황에서는 모든 DB에서 데이터 변경이 되지 않는 상황이었다고 했다. 3-Node간 복제 자체의 부하가 있다면 2-Node로 운영하며 리소스 부족시 Node를 추가하자고 제안하여 gcache사이즈 조정과 함께 야간에 작업이 진행되었다.
Galera Cluster 모니터링 준비 Galera Cluster관련 지표를 모니터링 프로그램에 추가하였다. MariaDB 모니터링 프로그램을 만든 이후 장애상황에 빠른 대응이 가능해졌다. 또한, 객관적인 성능지표를 근거로 고객/사업부를 설득하고 이해시킬 수 있는 장점이 있다.
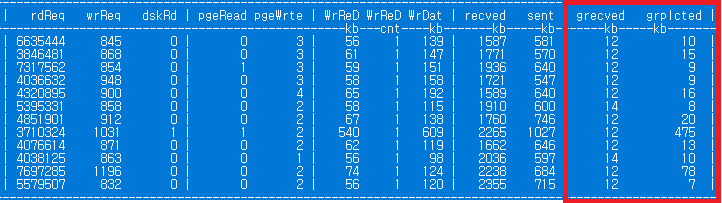
grecved(WSREP_RECEIVED_BYTES): Total size in bytes of all writesets received from other nodes. grplcted(WSREP_REPLICATED_BYTES): Total size in bytes of all writesets replicated to other nodes.
[Note]
gcache를 128MB에서 8GB로 상향하는 것은 실시간 운영중의 성능개선이 아니라 node를 새롭게 Galera Cluster에 Join시 node가 다운되어 있는 동안 Writesets을 보관하는 목적으로 gcache에 저장할 수 없을 정도로 커지면 DB를 snapshot하게되는 것에 영향을 주는 것이다.
쉽게 말해 node가 down되고 Galera Cluster에 Re-join될 때 down-time동안의 변경분을 적용 할 수 있는 Hold time을 결정하는 것이다. down-time이 Hold-time보다 크다면 DB의 snapshot이 적용되는 것이다.

Hold time = GCache size / Replication Rate.
Where: Replication Rate = Amount of replicated data / time. Amount of replicated data = (wsrep_replicated_bytes + wsrep_received_bytes) after the maintenance window - (wsrep_replicated_bytes + wsrep_received_bytes) before the maintenance window.
The amount of replicated data for the customer’s case = 7200MB.
Now, we can find out how much GCache (default 128M) can handle for the customer’s case:
Hold time = 128MB / (7200MB / 4h) = 128MB / 0.5 MB = 256s.
Then, we can calculate the right GCache size value to handle the maintenance window by the following formula: GCache = Maintenance window * Replication Rate = 14400s * 0.5 MB. GCache = 7200MB. 출처:https://severalnines.com/database-blog/understanding-gcache-galera
3일차: Connection Pool 부족 현상
서버 접근 권한을 받아 모니터링 시작하였다. Galera Cluster관련 지표는 수집시작.
Connection Pool 부족 모니터링(8개>50개 / WAS 6대 적용) WAS-DB간 Connection Pool설정이 기본값(8개)으로 셋팅되어 Connection을 얻기 위한 지연현상 발생함.
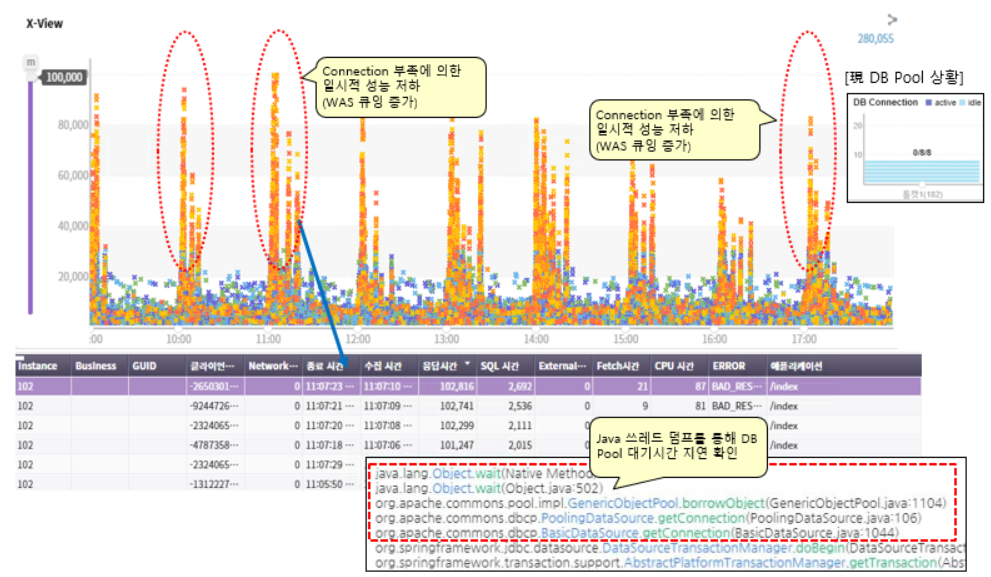
Connection Pool부족은 여러 사이트에서 발생하는 단골이슈로 해결은 Connection Pool수를 변경하면 된다. WAS재기동이 필요하므로 업무시간 이후에 POOL조정을 하기로 하였다. 간단하지만 결과는 2가지이다. 성능이슈가 해결되거나 Conneciton Pool부족으로 time-out으로 튕겨져 나가던 트랜잭션들이 DB로 들어오면서(처리량이 늘어나면서) 응답시간 지연이 발생하는 것이다.
(2편에 계속~)