
데브옵스 알아가기(4) : 3Ways - 제1방법
Updated:
본 포스팅에서는 앞서 예고한대로 『데브옵스 핸드북』 (진킴, 제즈험블 | 에이콘출판사 | 2016 )에 소개된 3Ways의 원칙과 개념 및 실천 방안에 대해서 알아볼 것이다. 분량이 많아 그 중에서 먼저 3Ways의 제1원칙에 대해서 설명한다.
데브옵스에서 갑툭튀 3Ways가 뭥미?라고 생각되는 분이 있다면 이 포스팅의 전편인 “데브옵스 알아가기3-구현전략 소개”편을 먼저 읽어 읽어볼 것을 추천한다.
또한 데브옵스 Basic에 해당하는 1, 2편도 열람한다면 본 내용을 이해하는데 더욱 도움이 될 것이다.
3Ways의 배경
3Ways는 데브옵스의 이론적 토대와 원칙을 제시한다. 요즘 데브옵스가 뜨다보니 무늬만 데브옵스인 경우가 많은데 진정한 데브옵스 구현을 바라는 조직이라면 3Ways는 반드시 알아야 할 개념이라고 생각된다.
데브옵스 사상은 천재적인 몇 사람의 발상으로부터 시작하여 기획되고 구상된 개념이 아니듯, 3Ways 또한 저자에 의해서 고안된 지적 산출물이 아니다. 운영-개발간의 갈등을 해결하고 싶었던 패트릭 드보아를 비롯하여 다양한 사람들, Agile 개발방식을 운영에도 접목하고 싶었던, 보다 효율적으로 운영을 할 수 있는 방법이 무엇인지 고민하였던 헌신적인 탐험가들에 의한 생각들이 담겨 있다고 보아야 한다.
애자일 선언
가장 큰 부분은 여러분도 알다시피 애자일 선언으로 촉발된 애자일 개발문화이다. 고객가치에 우선하여 신속하고 지속적으로 동작하는 제품을 전달하는 것은 애자일의 기본 원칙이며 데브옵스 역시 동일하다.
애자일 인프라
2008년 애자일 컨퍼런스에서 “애자일 인프라스트럭처”라는 주제로 세션이 개설되었다. 주최자인 앤드류 샤퍼는 효과적이고 효율적인 운영이 되기 위해서 어플리케이션 코드 영역이 아닌 인프라 영역에 집중하였고 애자일한 운영 환경에 대해 다양한 사람들과 논의하기를 원했다. 이 개념은 이 후 클라우드의 시대가 도래하면서 “코드로서의 인프라(Infrastructure as Code)”로 수렴하게 되었다.
린 운동
세번째는 린(Lean) 운동으로 꼽을 수 있다. 린 방식도 크게 보면 애자일 방법에 속한다고 볼 수 있겠지만, 프로세스의 낭비를 줄이고 작업의 크기를 줄여 최적의 업무 흐름을 통해 리드타임을 줄이고자 한 린 방식이야말로 데브옵스가 추구하는 방식이라 볼 수 있다.
존 앨스퍼와 폴 해먼드
두 사람은 “플리커(Flickr)”라는 야후의 온라인 사진 공유 커뮤니티 운영자이다. 2009년 벨로시티 컨퍼런스에서 그 유명한 “10 deploys per day : Dev and Ops Cooperation at Flickr”를 발표하였다. 총 78페이지로 되어 있는 이 자료(주로 그림이라 술술 읽힌다)를 보면 오늘날 데브옵스 원칙들의 초기 원형이 제시되고 있음을 볼 수 있다.
“운영은 안정화가 목표가 아니라 비지니스를 Enable하는 것이 목표이며, 그러기 위해서는 변화(Change)가 끊임없이 필요한데 Small Frequent Change로 가능하다”는 이야기를 비롯하여, 당시 시대상으로는 혁명적이고 주옥같은 내용들이 소개되어 있다. 이 발표를 들은 많은 참석자들은 큰 울림을 느꼈고, 패트릭 드보아 역시 영감을 받은 나머지 역사적인 devopsdays를 개최하는 계기가 되었다.
이제 본격적으로 3 Ways를 파헤쳐 보자.
3 Ways가 최초 언급된 것은 동일 저자인 진 킴에 의해서 2013년 『The Phoenix Project』에서였는데, 이후 진 킴은 데브옵스 핸드북스를 쓰면서 그 기초이론을 데브옵스의 이론과 원칙으로 발전시켰다. 본 블로그의 내용은 데브옵스 핸드북 본문 위주로 참고하였음을 밝혀둔다. 또한, 책의 내용을 필자 본인이 이해한 개념으로 바꾸어 설명하고자 하였는데, 이해가 어렵다면 원문을 그대로 찾아보시기 바란다.
3 Ways 개요
아래 그림을 포함하여 3Ways 개요에 대해서는 이미 전 편에서 소개한 적이 있다. 3Ways의 핵심 개념을 잘 표현하는 이미지로, 3Ways는 곧 System Flow, Feedback, Learning & Experimentation의 3가지 원칙에 대한 것이다.
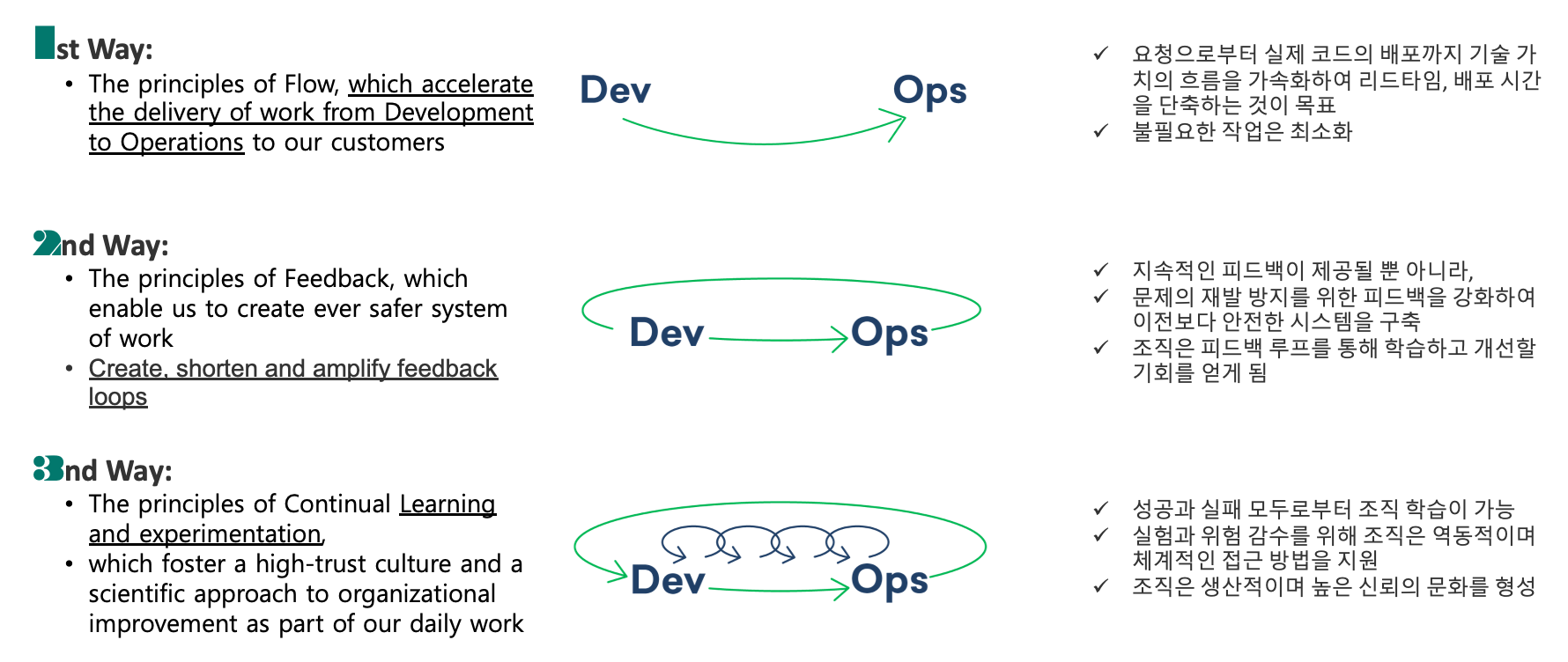
또한 이 3가지 원칙은 “기술가치흐름“에 집중하는데, 이를 개선하는 것이 3가지 원칙이 지향하는 바이다.
기술가치흐름이란 기존의 생산가치흐름에 대비되는 개념으로 기존에 미리 정해진 생산공정을 따라 작업이 흘러가면서 생산가치가 생성이 되듯, IT Technology 를 기반으로 한 작업 체계에서는 비즈니스 요구사항을 고객이 사용 가능한 서비스와 제품으로 전환하는 프로세스를 뜻한다.
한 마디로 이 업계의 말로 표현하자면 고객의 요청을 받아 개발/테스트/빌드/배포 등을 거쳐 출시하기까지 일련의 과정이다.

저자는 이 기술가치흐름을 단축시키거나 또는 더 자주 순환되도록 개선함으로써 고객에게 전달되는 가치가 증가된다고 보며, 이 흐름을 개선하기 위해 3ways 원칙을 적용해야 한다고 말한다.
1st Way : The principle of System Flow
첫번째 원칙은 개발에서 운영(=출시)까지 걸리는 기술가치흐름을 더욱 빠르게 하는 것이다.

고객 요청부터 출시까지 걸리는 시간은 “리드타임”이라 하는데, 이 리드타임을 줄이기 위한 원칙으로 다음과 같은 것들이 있다.
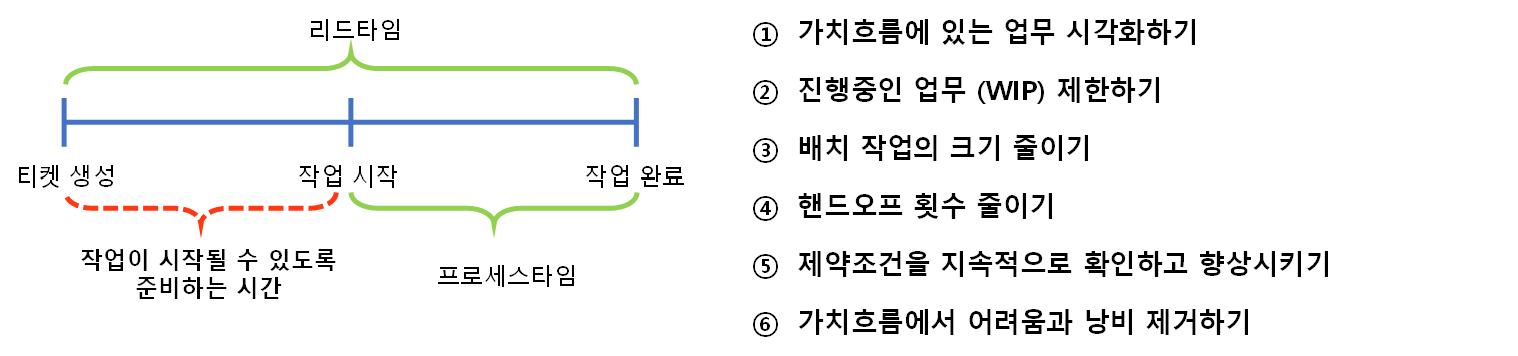
① 가치흐름에 있는 업무 시각화하기
리드타임 실제로 작업이 시작되기까지 걸리는 준비 시간과, 실제 작업이 진행되며 걸리는 시간(=프로세스 타임)으로 나누어 볼 수 있다.
전체 리드타임 단축의 목표를 가지는 경우 보통은 작업이 준비되는 시간에 대해서는 간과되며, 프로세스 타임에만 집중하기 마련하다. 설계와 코딩을 거쳐 테스트를 하는 핵심 과정 외에 각각의 작업이 관리자 또는 품질/보안 담당자에게 검토되고 승인 받는 과정이 있으며, 이 과정들은 장애 방지나 보안 등의 사유로 엄격히 통제를 받는다. 이러한 프로세스에서는 낭비를 제거하거나 단축할 만한 여지가 없어 보인다.
그러나, 이러한 일련의 과정들 속에도 표현되지 않는 업무들이 존재할 것이다. 따라서 먼저 가치흐름에 있는 모든 업무를 시각화하여 표현해본다면 이외의 작업들이 드러날 것이다. 구체적인 요구사항을 확인하기 위하여 회의를 소집하고 다 모이게 하는 거라든지, 변경관리위원회에 제출하기 위해 프린팅을 해야 하는데 보안으로 인해 직접 출력이 불가능하여 보안 담당자에게 출력할 내용을 보내고 대리 출력을 해야 한다든지, 또는 기술가치흐름에 직접 기여하지 않는 관계자들에게 변경사항을 공유하고 이해시키기 위한 설명 작업이 있다든지, ALM이라고 불리우는 공정관리 시스템에 나타나지 않는 과정들을 도식화하기만 해도, 거기 어딘가에 가치흐름을 단축할 만한 요소를 찾아낼 수 있다.
➁ 진행중인 업무 (WIP) 제한하기
일단 보이지 않았던 작업들의 시각화에 성공한다면, 진행중인 작업(WIP: Work In Process) 현황이나 Long Time이 소요되는 배치작업 등에 대해서도 식별이 가능할 것이다.

WIP*는 한 사람이 현재 작업중인 작업의 갯수를 나타내는데, 동시에 진행할 수 있는 WIP는 적정 개수 아래가 되도록 제한되어야 한다. Limit를 초과하여 진행되고 있다면 이는 일부 작업이 Holding 상태에 있다고 판단될 수 있다. 이는 과도한 작업자의 역량을 초과하는 할당으로 해당 업무가 지연되고 있거나, 혹은 작업 흐름에 어떤 방해물이 나타났음을 의미한다. 따라서 WIP를 적정 수준으로 제한하면, 특정 업무를 지연시키는 진짜 원인을 찾아낼 수 있다. 원활한 작업 흐름을 위해서는 WIP를 모니터링하여 작업이 지연되거나 방해받는 상황을 인지하고 원인을 찾아 이를 제거하는 활동을 해야 한다.
➂ 핸드오프 횟수 줄이기
핸드오프는 작업자 변경을 말하는데, WIP가 증가하면 그만큼 작업 전환에 따른 손실이 발생하기도 한다. 작업자가 A라는 업무를 진행하다가 미처 완료가 되지 않은 상태에서 B업무, C업무를 진행한 후, 다시 A업무로 돌아올 경우 각 A->B->C->A로 전환할 때마다 일부 업무 지식이 손실되기 마련이다.
산업혁명 이후 불과 얼마 전까지는 최대의 효율을 모토로 공정별로 전담 작업자가 지정되어 대량 생산하는 방식이 원가 절감 및 이익을 최대화하는 방법으로 여겨졌지만, 요즘의 비즈니스 전략은 똑같은 제품을 대량으로 찍어내는 방식이 아닌 고객의 수요에 맞춘 다 품종 소규모 생산 방식이 대세이다. 적은 수의 작업자가 한가지 제품 생산에 집중하므로 작업 전환에 따르는 손실이 줄어들 뿐 아니라, 스펙 변화시에도 빠르게 대응할 수 있다.
사실 IT업무에서는 개발된 S/W 하나 하나가 모두 유니크한 제품인데, 규모가 큰 시스템이나 조직에서 IT기획 or 업무분석가 -> 설계자 -> 개발자를 거치는 컨베이어 벨트식 개발 방법을 따르고 있다는 것은 좀 아이러니라는 생각이 든다. 심지어 제조 공정에서나 볼 수 있는 오프쇼어 전략으로 분석/설계는 국내 엔지니어를, 개발 과정은 해외 개발 도상국에 있는 프로그래머를 활용하는 방법을 얼마전까지 적극 따라 하였다. 위에서 이야기한 빠른 “기술가치흐름”에 전면 대치되는 방법이다. S/W개발에서 핸드오프에 따른 지식 손실을 줄이기 위해 지식의 자산화, 완벽한 설계 등을 강조하지만, 그보다는 핸드오프 그 자체를 줄이는 것이 효과적일 것 같다는 생각이 든다.
④ 배치 작업의 크기 줄이기
배치 작업*은 IT업계에서는 온라인 프로그램에 대치되는 것으로 통상 순차적으로 대량의 데이터를 처리하는 프로그램을 말하지만, 보다 일반적인 의미는 미리 정해진 순서에 따라 순차적으로 시행되는 일괄 작업을 말한다. 이러한 일괄 작업은 작업 단위의 생산성을 높이기 위한 목적으로 대량으로 작업을 한꺼번에 수행한 후에 다음 작업으로 넘어가기 마련이지만, 배치 작업이 중단될 경우 오히려 전체 흐름을 다시 시작해야 하므로 리드타임이 늘어나게 된다. 즉, IT요청을 처리하기 위해 누군가 대량의 작업을 처리한 후에 후속 작업자에게 넘겨야 한다면 첫번째 배치 작업의 크기가 클수록 후속 작업자는 늦게 시작하게 된다. 그러나 작업의 크기를 줄이게 되면 후속 배치 작업을 실행시키기까지의 대기 시간을 단축시킬 수 있을 뿐 아니라, 첫번째 완료된 결과물이 나오기까지의 시간도 줄어들게 된다. 이처럼 되기 위해서는 획기적인 사고 변화가 필요하다. 대부분의 작업자는 소규모 작업을 여러번 하기 보다는 한번에 작업을 끝내고 싶어하기 때문이다.
그 외 ⑤ 제약조건을 지속적으로 확인하고 향상시키기 / ⑥ 가치흐름에서 어려움과 낭비 제거하기 등의 방법이 있다.
System Flow를 위한 기술적 실천 방법
① 배포 파이프라인의 기반 생성
데브옵스를 기술적으로 실천하는 데에 있어 가장 기본적인 첫 걸음에 해당하는 내용이다.
배포 파이프라인의 기반이라 함은 개발, 테스트, 유사 프로덕션 환경(=스테이징)의 구축 및 개발 소스와 더불어 각종 환경을 만드는 데 필요한 설정 파일, 리소스 파일 등에 대한 단일 저장소를 만드는 것이다. 뭐, 이 정도는 굳이 데브옵스가 아니더라도 IT 운영팀이 전통적으로 이미 해오는 것일 수 있다.
데브옵스는 여기에 즉각적으로 사용 가능한 온-디맨드 개념을 더하는 것이 필요하다. 또는 코드형 인프라(IaC)를 도입함으로써, 프로그램이나 환경 설정 파일의 수정 없이 쉽고 빠른 환경을 마련하는 방법도 있다.
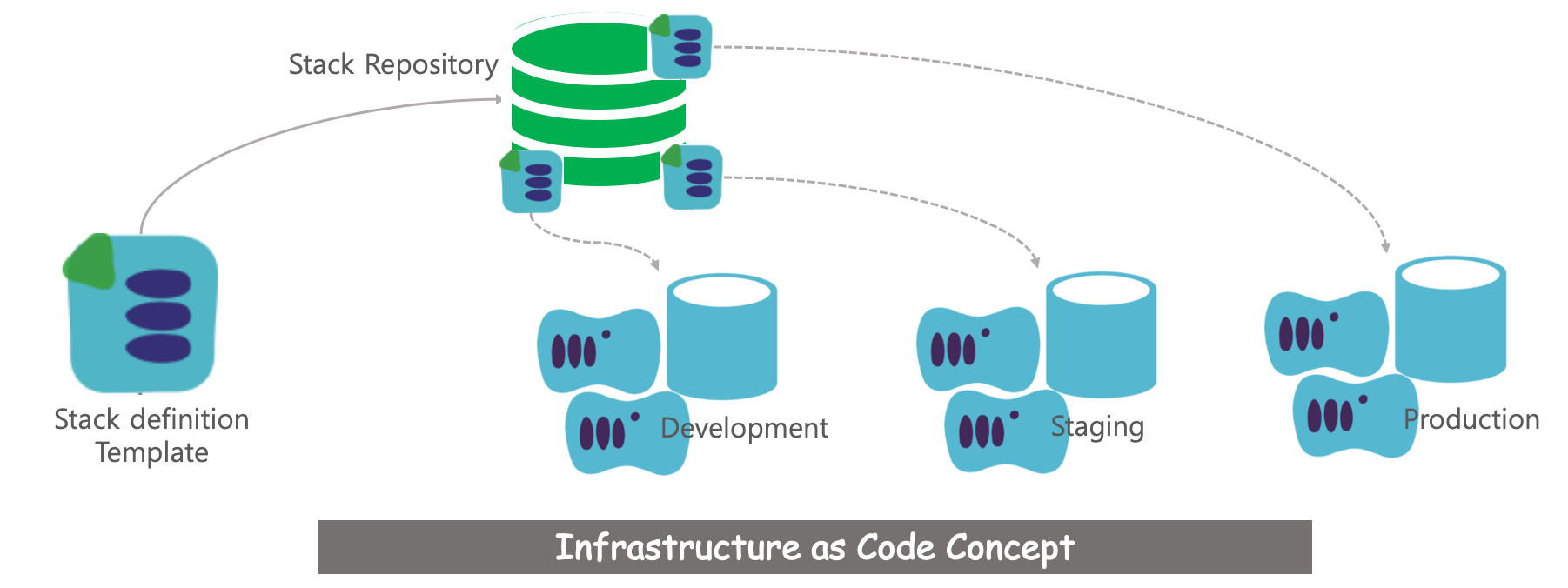
예전에 필자가 있었던 운영 조직에서는 NGMP, NGMS, NGMD, NGMB, NGMA, NGMX … 등 다양한 목적의 인스턴스를 구비해 놓았음에도 여러 개발 프로젝트와 운영팀의 테스트가 겹치지 않게 가용 가능한 테스트 일정을 확보하기 위하여 전쟁을 치뤄야 했던 적이 있다. 테스트 일정을 확보하더라도 인스턴스를 옮겨 다니며 프로그램을 일일이 배포하고, 데이터를 옮겨 놓는 일 또한 만만치 않은 일이다.
장애가 발생하면 늘상 “테스트가 부족했다, 환경 점검을 덜했다”라는 것을 원인 삼았으면서도, 정작 테스트를 위한 환경, 프로덕션으로 가기 이전에 그와 유사한 환경을 만들어 시뮬레이션해볼 수 있는 환경을 조성하는 것에는 소홀하지 않았나 싶다. 물론 이러한 일은 개인 혼자, 또는 프로젝트 단위로 가능한 일이 아니다. 또한 당시 기술로 초당 3,000~4,000 트랜잭션 발생하는 프로덕션 데이터를 유사 환경에 복제하는 일은, 월 단위의 준비가 필요한 작업이기도 했다.
어쨌든 이참에 데브옵스로 전환하려는 조직이 눈여겨봐야 할 대목이다. 앞서 1st Way 원칙에서 이야기했던 리드 타임을 단축하는 책임은 오롯이 운영자 개인이 전력질주해야 할 몫이 아니라 환경부터 만들어 나가야 한다는 뜻이다.
② 빠르고 신뢰할 수 있는 테스트 자동화
위와 같은 환경을 구성했다면, 다음에 해야 할 일은 무엇이겠는가? 각 인스턴스마다 돌아다니며 프로그램을 배포하고 테스트 데이터를 심고 결과를 확인해서 다시 돌려보는 일을 해야 한다. (원하는 기대값이 나올 때까지 무한반복)
이러한 반복이야말로 참으로 시간을 갉아먹는 지루한 시간이다. 그러나 테스트 자체는 너무 중요하기에 소홀히 할 수 없는 작업이다. 테스트 자동화를 하게 되면 이러한 중요한 작업을 단 몇 시간, 몇 분, 몇 초로 압축할 수 있게 된다. 물론 테스트 자동화를 하기 위해서는 매우 비싼 고급 툴이 필요하며, 자동화를 위해 준비해야 할 일들이 많거나 또는 잘못된 시나리오나 스크립트로 인해 자동화 테스트 결과가 무용지물이 될 수 있으므로 인터액티브(?)하게 사람이 개입해서 일일히 테스트를 하는 것이 오히려 효율적일 수 있다. 즉, 테스트 자동화에 따른 ROI는 미리 생각해 볼 여지는 있다.
하지만, 모든 케이스를 자동화할 수 없더라도 기존 기능에 대한 Regression 테스트, 또는 주로 야간에 실시하는 성능 테스트 등 많은 부분에서 자동화할 여지는 남아 있다.
데브옵스에서 “테스트 자동화”는 가장 핵심적인 프랙티스 중의 하나이다. 테스트가 자동화되지 않으면 지속적 배포/전달은 어렵다고 본다.
이를 위하여 책에서는 보다 구체적인 실행 방법을 열거하고 있는데, 데브옵스를 고민하고 있는 독자라면 책보다는 자신의 현장에서 자동화가 가능한 테스트 영역이 무엇인지 고민하고 실험적으로 적용해보는 것을 추천하고 싶다.
최근에는 다양한 테스트 도구가 오픈소스로 제공되고 있으니 참고하기 바란다.
| 분류 | 도구 명 | 비고 |
|---|---|---|
| Code Inspection & Analysis | SonarQube, SonaLint, FindSecurityBugs | |
| Source Code Test Coverage | Jacoco | |
| Function (API/UI) Test | Katalon | - Jenkins 등 기타 CI/CD 환경과 연계하기 위해 플러그인/라이브러리 등 설치가 필요할 수 있음 - UI 테스트를 위한 WebDriver, 패킷 확인을 위한 Fiddler 등 설치가 필요할 수 있음 |
| Performance Test | JMeter | 네트워크 대역폭이 많아야 동시 사용자 시뮬레이팅 가능 |
| Performance Test | Scouter, Sitespeed.io |
③ 지속적 통합의 실행 및 활성화
우선 소스 통합에 걸림돌이 되는 작업은 어떤 것들이 있을까? 어떤 경우에는 소스를 개발하는 작업 그 자체보다도 버전 관리 또는 브랜치 관리, 병합 및 회귀 테스트, 테스트 재현 등 소스 통합으로 인한 부수적인 작업들에 더 많은 시간이 소요되는 경우가 있다. 자동화 테스트를 통해 어느 정도 테스트 문제를 해결할 수는 있지만 브랜치 및 병합 부분에 있어서는 많은 시간이 소요되기 마련이다.
하지만 모든 브랜치와 병합이 문제되는 것은 아니다. 개발 생산성을 편리하기 위해 개발자마다 각자의 브랜치를 가져가거나, 또는 소스 통합을 몇 달 또는 몇 주 단위로 할 경우, 단순 개발보다 소스 통합에 훨씬 더 많은 시간이 걸릴 수 있다. 따라서 적정한 브랜치 수의 관리 및 버전 관리 정책이 필요하다. 무엇보다 소스의 통합을 더 자주 함으로써 병합을 쉽게 하고 테스트 시간 또한 단축할 수 있다. 이것이 지속적 통합(CI : Continuous Integration)의 개념이다.
책에서는 일일 단위로 커밋하고 테스트할 것을 권한다.(무조건 커밋은 아니고 테스트할 만한 기능 단위로 커밋을 하라는 의미이다). 자동화 테스트를 거쳐 검증된 소스는 그 즉시 자동화된 배포 프로세스에 의해 Pre-Production에 배포되고 고객이 원하는 일정에 맞추어 출시할 수 있게 된다. 지속적 배포 및 전달(CD : Continuous Deploy / Delivery)도 가능하게 되는 것이다.
④ 위험도가 낮은 출시를 위한 배포/출시 자동화
S/W 개발 라이프사이클 중에서 개발자들이 가장 긴장하는 순간은 마지막 배포/출시 단계이다. 모든 테스트를 마치고 출시되고 나면 무기물의 소스코드는 유기물화하여 마치 살아 있는 생물처럼 펄떡 거리기 시작한다. 모니터 상에 녹색과 빨간색 불이 왔다 갔다 하는 동안도 침이 마르지만, 갑자기 그래프가 튀어 오르고 전화 벨이 오르면 아드레날린도 같이 용솟음친다. 출시하는 프로그램이 그 무엇이건 간에, 출시 후 대기하는 순간만큼은 초긴장의 상태를 면할 수 없는 것이다. 사이가 좋던 개발팀과 운영팀이 칼같이 니꺼 내꺼 영역을 나누게 되는 것도 이 순간 때문이다.
어떤 IT운영부서가 고객사의 바램대로 데브옵스를 도입한 다음, 더 잦은 배포를 하게 되어 매우 우울해졌다라는 이야기는 이러한 현실을 반영한다. 지속적인 통합과 배포로 고객의 행복을 달성한 만큼, 개발자가 불행해져서야 되겠는가 !
책에서는 데브옵스 선구자들이 이를 해결하기 위한 방법으로 배포/출시 과정 자체를 자동화하고, 배포와 출시 작업을 분리하며, 안전한 출시가 가능하도록 유사 프로덕션 환경을 둘 것을 제안한다. 카나리아 또는 블루-그린 방식을 사용하여 배포와 출시 작업을 분리하면 출시에 임박하여 많은 시간을 대기하지 않고 미리 배포를 할 수 있다.
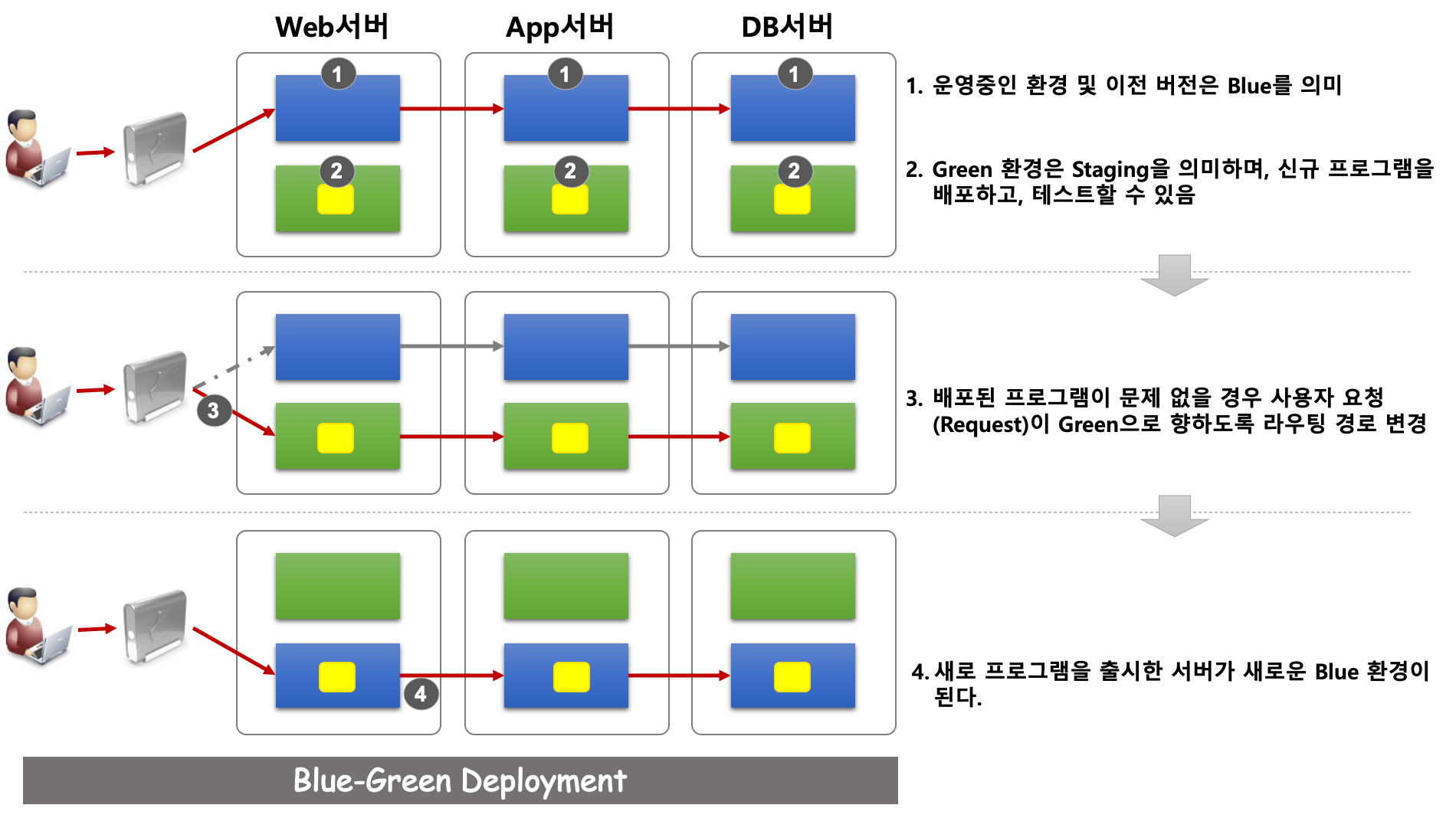 배포 프로세스의 자동화는 Cloud를 많이 쓰는 요즘과 같은 상황에서는 이미 당연시 여겨지는 것이지만, 기존 레거시 환경에서는 거의 모든 배포 과정이 수작업으로 이루어졌다. Jenkins 기능을 이용하면 미리 작성해둔 스크립트에 의해 원하는 위치로 리소스 파일이 복사 또는 전송될 뿐 아니라 프로그램 빌드 , Config 파일의 수정, 동작 여부 확인 등이 순차적으로 처리된다.
배포 프로세스의 자동화는 Cloud를 많이 쓰는 요즘과 같은 상황에서는 이미 당연시 여겨지는 것이지만, 기존 레거시 환경에서는 거의 모든 배포 과정이 수작업으로 이루어졌다. Jenkins 기능을 이용하면 미리 작성해둔 스크립트에 의해 원하는 위치로 리소스 파일이 복사 또는 전송될 뿐 아니라 프로그램 빌드 , Config 파일의 수정, 동작 여부 확인 등이 순차적으로 처리된다.
⑤ 위험도가 낮은 출시를 위한 아키텍처 구현
안전한 출시를 위해서는 기존 아키텍처를 과감히 바꾸어야 할 수도 있다.
어차피 엔트로피 법칙에 의하면 아무리 정교한 시스템일지라도 시간이 지날수록 망가지기 쉽상이고, 복잡도 증가와 장애 위협의 증가로 인하여 유지보수는 점점 더 어려워진다. 오래된 아키텍처는 새로운 혁신적인 기술을 써먹기엔 너무 위험하므로 기술부채는 쌓여만 간다.
복잡해진 시스템을 리팩토링하여 단순화하고 기술부채의 해결을 위해 주기적인 아키텍처 개선 작업이 필요하지만, 데브옵스 월드의 CI/CD를 위해서는 보다 더 안전한 아키텍처로 전환할 필요가 있다. 이른 바 위에서 이야기한 배포/출시 단계의 초긴장 대기 상태를 극복하기 위해서는 프로그램 배포 후 발생할 장애의 가능성을 애초에 줄이기 위한 시도가 필요한 것이다. 이에 대한 대안이 바로 마이크로서비스 아키텍처(MSA)이다. 보통 모놀리식 구조에서는 하나의 프로그램 오류가 전체 시스템 Down으로까지 확산될 영향이 크지만, 마이크로서비스 구조를 구현하게 되면 프로그램 오류 발생시 기껏해야 영향 받는 범위는 마이크로서비스 하나이다.

완벽한 마이크로서비스 구조에서는 타 서비스에 미치는 영향도가 획기적으로 줄어들기 때문에 프로그램 배포와 출시를 보다 안전하게 진행할 수 있을 뿐 아니라, 소스 통합 및 테스트에 소요되는 부담 또한 적어지므로 그만큼 민첩해진다고도 볼 수 있다. 단, 마이크로서비스를 구현하는 기술 자체는 복잡하며, 구현이 어려우므로 무조건 MSA를 도입한다고 해서 효과를 볼 수 있는 것은 아니므로 업무 성격을 판단하여 적용을 판단해야 한다.
정리
이상 3 Ways의 첫번째 방법에 대해 살펴보았다.
전체 3가지 방법 중 하나만 보았는데도 Insight가 팍팍 생기는 것 같다. 그동안 리드타임 단축을 그토록 외쳐왔는데, “쥐어 짜는” 방식이 아니라 체계적이고 안전하면서도 민첩하게 일할 수 있는 방식으로 개선할 수 있다는 게 신기하다. 물론 이러한 원칙과 기술적 방법이 현실로 구체화 되기가 쉽지는 않을 것이다.
그러나, 어렵다고 변명하기에는 이미 많은 조직에서 실천하고 있고 검증되고 있다.
다음 편에서는 제2 방법에 대해 알아보겠다.
본 블로그의 주된 내용은 다음을 참고하여 작성하였음을 밝힙니다.
< EOF >